




This is a test post with math formulas: \(A=(a_{ij})\).
Equation: $$ \operatorname{erf} x = {2\over\sqrt{\pi}} \int_0^x e^{-t^2}dt $$
date: "2021-01-16 13:09:13" title: "Unitymedia und SIP VoIP" slug: blog-2021-01-16-unitymedia-und-sip-voip draft: false categories: ["network"] tags: ["Unitymedia"]
author: "Elmar Klausmeier"
This post was automatically copied from Unitymedia und SIP VoIP on eklausmeier.goip.de.
Folgendes schrieb ich an die Firma Unitymedia, jetzt Vodafone:
ich möchte gerne meine Rufnummer XXX über meine YYY Telefonanlage via VoIP betreiben. Ich verwende den von Ihnen bereitgestellten Router "Vodafone Station". Meine Kundennummer lautet ZZZ. Ich benötige nun folgende sieben Informationen: 1. Domain 2. Registrar 3. STUN-Server 4. Outbound-Proxy 5. SIP-UDP Port 6. Benutzername 7. Passwort
Antwort von Unitymedia nach einmaliger Erinnerung:
Unitymedia Telefon arbeitet mit der Technologie "PacketCable". Im Gegensatz zu konkurrierenden, auf DSL-basierenden Internettelefonie-Angeboten, werden die Sprachdaten bzw. -pakete dabei nicht über das Internet transportiert. Die IP-basierte Übermittlung erfolgt ausschließlich im gesicherten Unitymedia-Netz, welches vom eigenen Kontrollzentrum (Unitymedia Network Operation Center in Kerpen) permanent überwacht und gesteuert wird. So können wir eine hohe Dienstequalität ("Quality of Service") und Verfügbarkeit garantieren, die bei internetbasierten Voice-over-IP-Lösungen nicht zugesagt werden können. Die SIP Daten werden nur rausgegeben wenn Sie sich einen eigenen Router anschaffen. Um die Daten dann in Ihrer Fritzbox (o.ä) eintragen. Bei unseren Routern werden die SIP Daten von unseren Servern generiert. Deswegen können wir die SIP Daten Ihnen nicht geben.
Vielleicht hilft dies anderen bei ähnlichen Anliegen.
date: "2021-01-23 09:30:00" title: "dumpe2fs: When was my hard-drive first formatted?" slug: blog-2021-01-23-dumpe2fs-when-was-my-hard-drive-first-formatted draft: false categories: ["Linux"] tags: ["dumpe2fs"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from dumpe2fs: When was my hard-drive first formatted? on eklausmeier.goip.de.
I repeatedly forget to remember when my hard-drive or SSD was first formatted.
Command for this is dumpe2fs. This command is part of package e2fsprogs. Example:
# dumpe2fs -h /dev/sda1
dumpe2fs 1.45.6 (20-Mar-2020)
Filesystem volume name: <none>
Last mounted on: /boot
Filesystem UUID: 83a1bedb-6fd3-46d0-8900-e4e09536168e
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype sparse_super
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 62248
Block count: 248832
Reserved block count: 12441
Free blocks: 126393
Free inodes: 61933
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 256
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2008
Inode blocks per group: 251
RAID stride: 4
RAID stripe width: 4
Filesystem created: Mon Apr 21 13:45:32 2014
Last mount time: Sun May 31 14:18:09 2020
Last write time: Mon Jun 1 00:40:25 2020
Mount count: 35
Maximum mount count: -1
You must be root to use this command. It does not work for encrypted disks (LUKS) or volume groups.
date: "2021-02-01 11:00:50" title: "Performance comparison Ryzen vs. Intel vs. Bulldozer vs. ARM" slug: blog-2021-02-01-performance-comparison-ryzen-vs-intel-vs-bulldozer-vs-arm draft: false categories: ["C / C++", "programming"] author: "Elmar Klausmeier" MathJax: true
prismjs: true
This post was automatically copied from Performance comparison Ryzen vs. Intel vs. Bulldozer vs. ARM on eklausmeier.goip.de.
For comparing different machines I invert the Hilbert matrix
$$
H = \left(\begin{array}{ccccc} 1 & {1\over2} & {1\over3} & \cdots & {1\over n} \\
{1\over2} & {1\over3} & {1\over4} & \cdots & {1\over n+1} \\
{1\over3} & {1\over4} & {1\over5} & \cdots & {1\over n+2} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
{1\over n} & {1\over n+1} & {1\over n+2} & \cdots & {1\over2n-1}
\end{array} \right)
= \left( {\displaystyle {1\over i+j-1} } \right)_{ij}
$$
This matrix is known have very high condition numbers. Program xlu5.c stores four double precision matrices of dimension \(n\). Matrix H and A store the Hilbert matrix, X is the identity matrix, Y is the inverse of H. Finally the maximum norm of \(I-H\cdot H^{-1}\) is printed, which should be zero. These four double precision matrices occupy roughly 1.6 MB for \(n=230\).
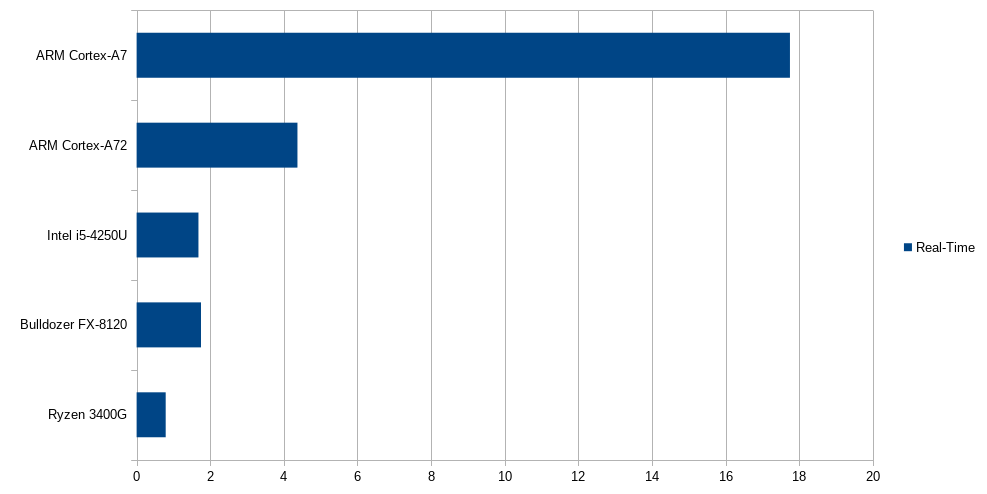
1. Runtime on Ryzen, AMD Ryzen 5 PRO 3400G with Radeon Vega Graphics, max 3.7 GHz, as given by lscpu.
$ time xlu5o3b 230 > /dev/null
real 0.79s
user 0.79s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 128 KiB
L1i cache: 256 KiB
L2 cache: 2 MiB
L3 cache: 4 MiB
Required storage for above program is 4 matrices, each having 230x230 entries with double (8 bytes), giving 1692800 bytes, roughly 1.6 MB.
2. Runtime on AMD FX-8120, Bulldozer, max 3.1 GHz, as given by lscpu.
$ time xlu5o3b 230 >/dev/null
real 1.75s
user 1.74s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 64 KiB
L1i cache: 256 KiB
L2 cache: 8 MiB
L3 cache: 8 MiB
3. Runtime on Intel, Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz, max 2.6 GHz, as given by lscpu.
$ time xlu5o3b 230 > /dev/null
real 1.68s
user 1.67s
sys 0
swapped 0
total space 0
Cache sizes within CPU are:
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 512 KiB
L3 cache: 3 MiB
Apparently the Ryzen processor can outperform the Intel processor on cache, higher clock frequency. But even for smaller matrix sizes, e.g., 120, the Ryzen is two times faster.
Interestingly, the error in computations are different!
AMD and Intel machines run ArchLinux with kernel version 5.9.13, gcc was 10.2.0.
4. Runtime on Raspberry Pi 4, ARM Cortex-A72, max 1.5 GHz, as given by lscpu.
$ time xlu5 230 > /dev/null
real 4.37s
user 4.36s
sys 0
swapped 0
total space 0
Linux 5.4.83 and GCC 10.2.0.
5. Runtime on Odroid XU4, Cortex-A7, max 2 GHz, as given by lscpu.
$ time xlu5 230 > /dev/null
real 17.75s
user 17.60s
sys 0
swapped 0
total space 0
So the Raspberry Pi 4 is clearly way faster than the Odroid XU4.
date: "2021-02-09 17:15:59" title: "Poisson Log-Normal Distributed Random Numbers" slug: blog-2021-02-09-poisson-log-normal-distributed-random-numbers draft: false categories: ["Uncategorized"] author: "Elmar Klausmeier"
MathJax: true
This post was automatically copied from Poisson Log-Normal Distributed Random Numbers on eklausmeier.goip.de.
Task at hand: Generate random numbers which follow a lognormal distribution, but this drawing is governed by a Poisson distribution. I.e., the Poisson distribution governs how many lognormal random values are drawn. Input to the program are \(\lambda\) of the Poisson distribution, modal value and either 95% or 99% percentile of the lognormal distribution.
From Wikipedia's entry on Log-normal distribution we find the formula for the quantile \(q\) for the \(p\)-percentage of the percentile \((0<p<1)\), given mean \(\mu\) and standard deviation \(\sigma\): $$ q = \exp\left( \mu + \sqrt{2}\,\sigma\, \hbox{erf}^{-1}(2p-1)\right) $$ and the modal value \(m\) as $$ m = \exp\left( \mu - \sigma^2 \right). $$ So if \(q\) and \(m\) are given, we can compute \(\mu\) and \(\sigma\): $$ \mu = \log m + \sigma^2, $$ and \(\sigma\) is the solution of the quadratic equation: $$ \log q = \log m + \sigma^2 + \sqrt{2}\,\sigma\, \hbox{erf}^{-1}(2p-1), $$ hence $$ \sigma_{1/2} = -{\sqrt{2}\over2}\, \hbox{erf}^{-1}(2p-1) \pm\sqrt{ {1\over2}\left(\hbox{erf}^{-1}(2p-1)\right)^2 - \log(m/q) }, $$ or more simple $$ \sigma_{1/2} = -R/2 \pm \sqrt{R^2/4 - \log(m/q) }, $$ with $$ R = \sqrt{2}\,\hbox{erf}^{-1}(2p-1). $$ For quantiles 95% and 99% one gets \(R\) as 1.64485362695147 and 2.32634787404084 respectively. For computing the inverse error function I used erfinv.c from lakshayg.
Actual generation of random numbers according Poisson- and lognormal-distribution is done using GSL. My program is here: gslSoris.c.
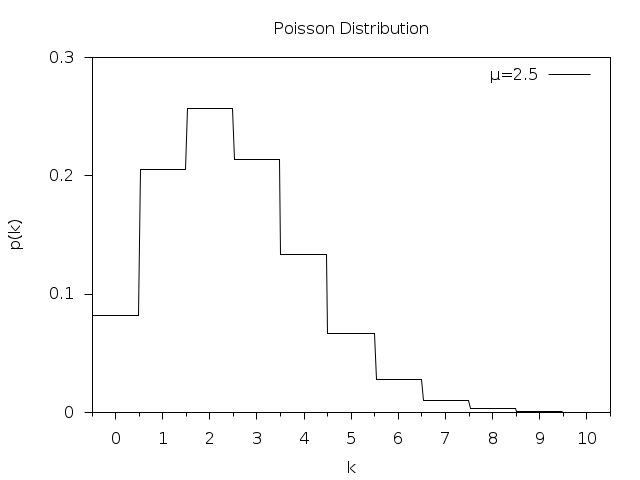
Poisson distribution looks like this (from GSL documentation):
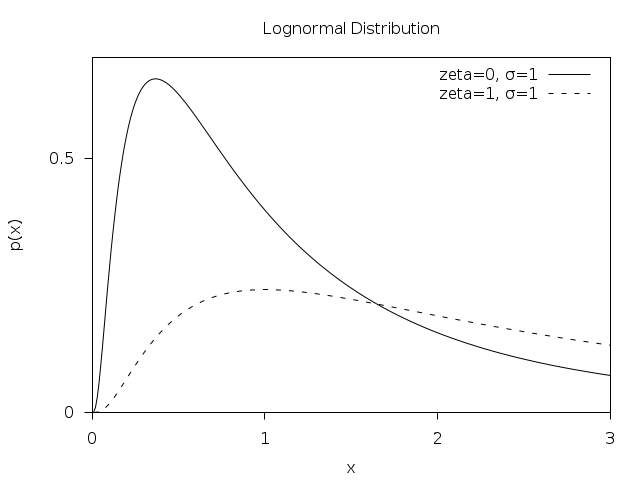
Lognormal distribution looks like this (from GSL):
date: "2021-02-21 21:00:53" title: "ssh as SOCKS server" slug: blog-2021-02-21-ssh-as-socks-server draft: false categories: ["Linux", "network", "security"] tags: ["ssh"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from ssh as SOCKS server on eklausmeier.goip.de.
Assume three computers A, B, and C. A can connect to B via ssh, but A cannot connect to C, but B can connect to C.
A -> B -> C
On A open ssh as SOCKS-server with
ssh -N -D 9020 user@B
Now on A one can use
brave --proxy-server="socks5://localhost:9020"
The browser will then show up as if directly surfing on B thereby circumventing the limitations on A.
Instead of the brave browser, one can use Chromium, or Firefox. Option "-N": Do not execute a remote command.
See How to Set up SSH SOCKS Tunnel for Private Browsing, or SOCKS.
date: "2021-02-28 21:00:55" title: "Analysis And Usage of SSHGuard" slug: blog-2021-02-28-analysis-and-usage-of-sshguard draft: false categories: ["network", "security", "Linux"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Analysis And Usage of SSHGuard on eklausmeier.goip.de.
To ban annoying ssh access to your Linux box you can use fail2ban. Or, alternatively, you can use SSHGuard. SSHGuard's installed size is 1.3 MB on Arch Linux. Its source code, including all C-files, headers, manuals, configuration, and makefiles is 8 KLines. In contrast, for fail2ban just the Python source code of version 0.11.2 is 31 KLines, not counting configuration files, manuals, and text files; its installed size is 3.3 MB. fail2ban is also way slower than SSHGuard. For example, one one machine fail2ban used 7 minutes of CPU time, where SSHGuard used 11 seconds. I have written on fail2ban in "Blocking Network Attackers", "Chinese Hackers", and "Blocking IP addresses with ipset".
SSHGuard is a package in Arch Linux, and there is a Wiki page on it.
1. Internally SSHGuard maintains three lists:
- whitelist: allowed IP addresses, given by configuration
- blocklist: list of IP addresses which are blocked, but which can become unblocked after some time, in-memory only
- blacklist: permanently blocked IP addresses, stored in cleartext in file
SSHGuard's main function is summarized in below excerpt from its shell-script /bin/sshguard.
eval $tailcmd | $libexec/sshg-parser | \
$libexec/sshg-blocker $flags | $BACKEND &
wait
There are four programs, where each reads from stdin and writes to stdout, and does a well defined job. Each program stays in an infinite loop.
$tailcmdreads the log, for example viatail -f, which might contain the offending IP addresssshg-parserparses stdin for offending IP'ssshg-blockerwrites IP addresses$BACKENDis a firewall shell script which either usesiptables,ipset,nft, etc.
sshg-blocker in addition to writing to stdout, also writes to a file, usually /var/db/sshguard/blacklist.db. This is the blacklist file. The content looks like this:
1613412470|100|4|39.102.76.239
1613412663|100|4|62.210.137.165
1613415749|100|4|39.109.122.173
1613416009|100|4|80.102.214.209
1613416139|100|4|106.75.6.234
1613418135|100|4|42.192.140.183
The first entry is time in time_t format, second entry is service, in our case always 100=ssh, third entry is either 4 for IPv4, or 6 for IPv6.
SSHGuard handles below services:
enum service {
SERVICES_ALL = 0, //< anything
SERVICES_SSH = 100, //< ssh
SERVICES_SSHGUARD = 110, //< SSHGuard
SERVICES_UWIMAP = 200, //< UWimap for imap and pop daemon
SERVICES_DOVECOT = 210, //< dovecot
SERVICES_CYRUSIMAP = 220, //< cyrus-imap
SERVICES_CUCIPOP = 230, //< cucipop
SERVICES_EXIM = 240, //< exim
SERVICES_SENDMAIL = 250, //< sendmail
SERVICES_POSTFIX = 260, //< postfix
SERVICES_OPENSMTPD = 270, //< OpenSMTPD
SERVICES_COURIER = 280, //< Courier IMAP/POP
SERVICES_FREEBSDFTPD = 300, //< ftpd shipped with FreeBSD
SERVICES_PROFTPD = 310, //< ProFTPd
SERVICES_PUREFTPD = 320, //< Pure-FTPd
SERVICES_VSFTPD = 330, //< vsftpd
SERVICES_COCKPIT = 340, //< cockpit management dashboard
SERVICES_CLF_UNAUTH = 350, //< HTTP 401 in common log format
SERVICES_CLF_PROBES = 360, //< probes for common web services
SERVICES_CLF_LOGIN_URL = 370, //< CMS framework logins in common log format
SERVICES_OPENVPN = 400, //< OpenVPN
SERVICES_GITEA = 500, //< Gitea
};
2. A typical configuration file might look like this:
LOGREADER="LANG=C /usr/bin/journalctl -afb -p info -n1 -t sshd -o cat"
THRESHOLD=10
BLACKLIST_FILE=10:/var/db/sshguard/blacklist.db
BACKEND=/usr/lib/sshguard/sshg-fw-ipset
PID_FILE=/var/run/sshguard.pid
WHITELIST_ARG=192.168.178.0/24
Furthermore one has to add below lines to /etc/ipset.conf:
create -exist sshguard4 hash:net family inet
create -exist sshguard6 hash:net family inet6
Also, /etc/iptables/iptables.rules and /etc/iptables/ip6tables.rules need the following link to ipset respectively:
-A INPUT -m set --match-set sshguard4 src -j DROP
-A INPUT -m set --match-set sshguard6 src -j DROP
3. Firewall script sshg-fw-ipset, called "BACKEND", is essentially:
fw_init() {
ipset -quiet create -exist sshguard4 hash:net family inet
ipset -quiet create -exist sshguard6 hash:net family inet6
}
fw_block() {
ipset -quiet add -exist sshguard$2 $1/$3
}
fw_release() {
ipset -quiet del -exist sshguard$2 $1/$3
}
...
while read -r cmd address addrtype cidr; do
case $cmd in
block)
fw_block "$address" "$addrtype" "$cidr";;
release)
fw_release "$address" "$addrtype" "$cidr";;
flush)
fw_flush;;
flushonexit)
flushonexit=YES;;
*)
die 65 "Invalid command";;
esac
done
The "BACKEND" is called from sshg-blocker as follows:
static void fw_block(const attack_t *attack) {
unsigned int subnet_size = fw_block_subnet_size(attack->address.kind);
printf("block %s %d %u\n", attack->address.value, attack->address.kind, subnet_size);
fflush(stdout);
}
static void fw_release(const attack_t *attack) {
unsigned int subnet_size = fw_block_subnet_size(attack->address.kind);
printf("release %s %d %u\n", attack->address.value, attack->address.kind, subnet_size);
fflush(stdout);
}[/code]
SSHGuard is using the list-implementation [SimCList](https://mij.oltrelinux.com/devel/simclist/) from [Michele Mazzucchi](https://ch.linkedin.com/in/mmazzucchi).
<strong>4. </strong>sshg-parser uses [flex](https://en.wikipedia.org/wiki/Flex_(lexical_analyser_generator)) (=lex) and [bison](https://en.wikipedia.org/wiki/GNU_Bison) (=yacc) for evaluating log-messages. An introduction to flex and bison is [here](https://www.oreilly.com/library/view/flex-bison/9780596805418/ch01.html). Tokenization for ssh using flex is:
```C
"Disconnecting "[Ii]"nvalid user "[^ ]+" " { return SSH_INVALUSERPREF; }
"Failed password for "?[Ii]"nvalid user ".+" from " { return SSH_INVALUSERPREF; }
Actions based on tokens using bison is:
%token SSH_INVALUSERPREF SSH_NOTALLOWEDPREF SSH_NOTALLOWEDSUFF
msg_single:
sshmsg { attack->service = SERVICES_SSH; }
| sshguardmsg { attack->service = SERVICES_SSHGUARD; }
. . .
;
/* attack rules for SSHd */
sshmsg:
/* login attempt from non-existent user, or from existent but non-allowed user */
ssh_illegaluser
/* incorrect login attempt from valid and allowed user */
| ssh_authfail
| ssh_noidentifstring
| ssh_badprotocol
| ssh_badkex
;
ssh_illegaluser:
/* nonexistent user */
SSH_INVALUSERPREF addr
| SSH_INVALUSERPREF addr SSH_ADDR_SUFF
/* existent, unallowed user */
| SSH_NOTALLOWEDPREF addr SSH_NOTALLOWEDSUFF
;
Once an attack is noticed, it is just printed to stdout:
static void print_attack(const attack_t *attack) {
printf("%d %s %d %d\n", attack->service, attack->address.value,
attack->address.kind, attack->dangerousness);
}
5. For exporting fail2ban's blocked IP addresses to SSHGuard one would use below SQL:
select ip from (select ip from bans union select ip from bips)
to extract from /var/lib/fail2ban/fail2ban.sqlite3.
6. In case one wants to unblock an IP address, which got blocked inadvertently, you can simply issue
ipset del sshguard4 <IP-address>
in case you are using ipset as "BACKEND". If this IP address is also present in the blacklist, you have to delete it there as well. For that, you must stop SSHGuard.
date: "2021-03-02 17:30:56" title: "Testing J-Pilot feature-gtk3 branch" slug: blog-2021-03-02-testing-j-pilot-feature-gtk3-branch draft: false categories: ["J-Pilot", "Linux"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Testing J-Pilot feature-gtk3 branch on eklausmeier.goip.de.
J-Pilot still relies on GTK+ 2, which is heading towards planned deprecation. The entire work to migrate to GTK+ 3 is done by volunteers, Judd Montgomery and David Malia. This post is about testing this new experimental branch feature-gtk3 from GitHub.
Installing this branch is straightforward:
- Download zip-file and unpack
- Run
autogen.sh, then runmake - Create virgin directory
\\(HOME/tmp/gtk3/and copyempty/*.pdbto\\)HOME/tmp/gtk3/.jpilot, otherwise no records will be shown in GUI
Below is a list of warnings, errors and crashes for version d558d56 from 25-Feb-2021.
W1. Starting
JPILOT_HOME=$HOME/tmp/gtk3/ ./jpilot
shows
(jpilot:42580): Gtk-CRITICAL **: 14:22:57.546: gtk_list_store_get_path: assertion 'iter->stamp == priv->stamp' failed
(jpilot:42580): Gtk-CRITICAL **: 14:22:57.546: gtk_tree_selection_select_path: assertion 'path != NULL' failed
(jpilot:42580): Gtk-CRITICAL **: 14:22:57.546: gtk_list_store_get_path: assertion 'iter->stamp == priv->stamp' failed
(jpilot:42580): Gtk-CRITICAL **: 14:22:57.546: gtk_tree_selection_select_path: assertion 'path != NULL' failed
E1. Importing from a hidden directory no longer works, as hidden directory is not shown. In "old" J-Pilot you could specify the hidden directory in edit-field and then press TAB. (No longer the case with ba8354f.)
E2. Searching crashes. (No longer the case with ba8354f.)
segmentation fault (core dumped) JPILOT_HOME=$HOME/tmp/gtk3/ ./jpilot
Running J-Pilot from within gdb and then searching results in:
Thread 1 "jpilot" received signal SIGSEGV, Segmentation fault.
0x00007ffff71facd6 in g_type_check_instance_cast () from /usr/lib/libgobject-2.0.so.0
Executable has debug symbols:
$ file jpilot
jpilot: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=745cb795eccaf42d04e2920ca592534a72dbf1f4, for GNU/Linux 4.4.0, with debug_info, not stripped
E3. Address book entries look "awful", i.e., entries are too close together. (No longer the case with ba8354f.)
Address records:
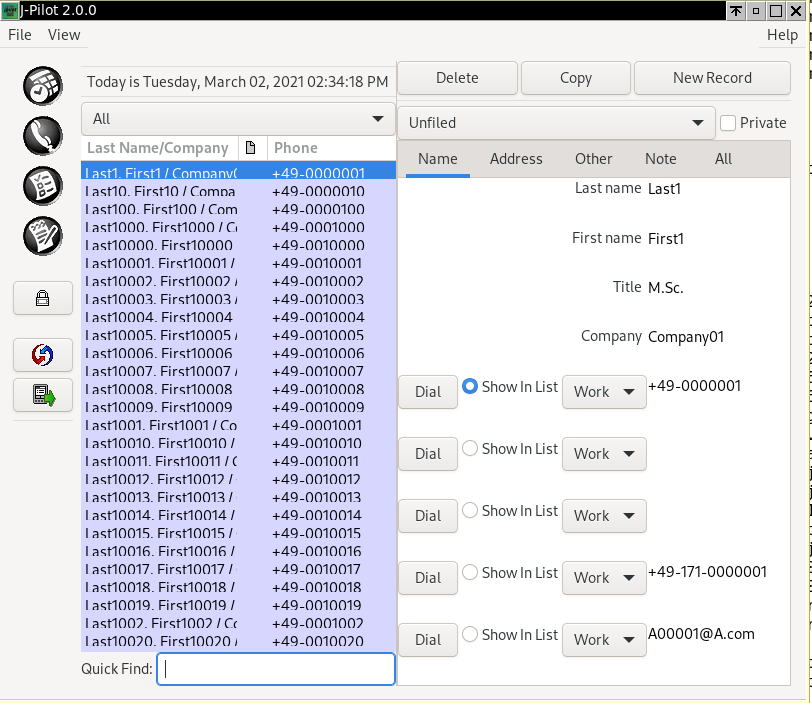 Date records:
Date records:
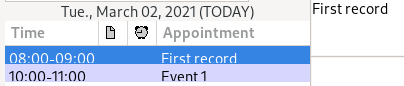 Also, entering entirely new address record doesn't show separation lines betweeen fields:
Also, entering entirely new address record doesn't show separation lines betweeen fields:
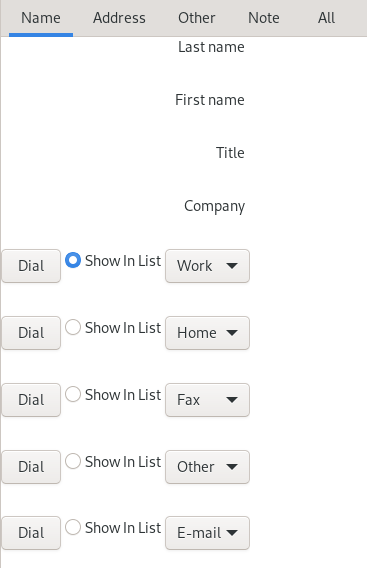
U1. To quickly get "mass"-data for a possible buggy J-Pilot software, I prepared a Perl script palmgencsv to generate address- and datebook-CSV files. For example:
$ palmgencsv -dn12000 > d12k.csv
generates 12-thousand records for datebook. Likewise:
$ palmgencsv -an15000 > a15k.csv
generates 15-thousand address records.
C1. One admirable feature, which does work with GTK+ 3, is using the "Broadway backend":
broadwayd &
export JPILOT_HOME=$HOME/tmp/gtk3/
GDK_BACKEND=broadway ./jpilot
Alternatively, one could use broadwayd --address 0.0.0.0. Fire up a web-browser and visit http://localhost:8080/. This will show J-Pilot running within the web-browser:
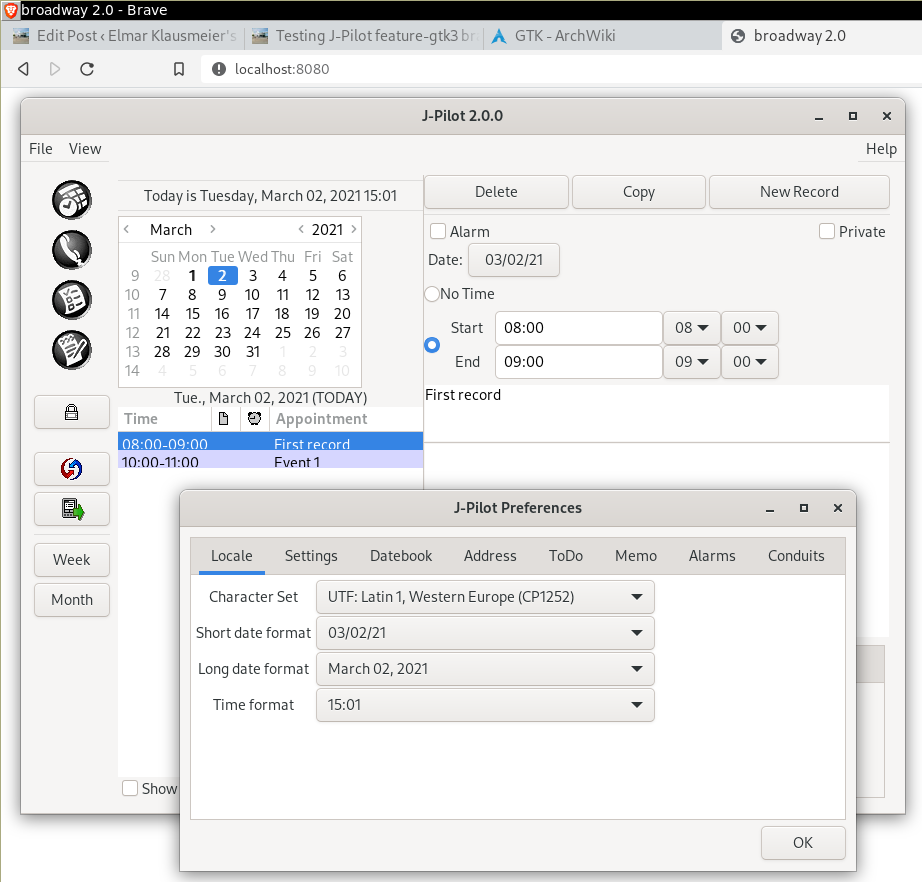 How cool is that?
How cool is that?
Added 21-Mar-2021: I retested with ba8354f = "Merge pull request #27 from dmalia1/fix-unfocused-color-theme".
Importing from hidden directories: Works. Tested importing 23-thousand address records, 21-thousand date records from hidden directory.
Search does no longer crash immediately (sounds worse than it really is) As noted in the blog-post I created a Perl-script to generate masses of data. I generated 12-thousand date records (palmgencsv -dn12000). In this case, I created date records Event 1, Event 2, ..., Event 12000. When I search for "Event" (no number), search-window will show me all 12-thousand entries correctly. But when I narrow the search to Event 12000 in the same search-window, then J-Pilot hangs. I tested the same with J-Pilot 1.8.2, which does not exhibit this behaviour. I agree that this is extreme. When I repeat with fewer search matches, e.g., just hundred or just thousand search results and then narrowing, then this hang does not occur. The hang shows no CPU time -- it just hangs, and I lost patience and closed search-window, which also closed the main J-Pilot window.
Entries in address book look better now.
Starting J-Pilot shows:
(jpilot:49290): Gtk-CRITICAL **: 21:05:20.459: gtk_list_store_get_path: assertion 'iter->stamp == priv->stamp' failed
(jpilot:49290): Gtk-CRITICAL **: 21:05:20.459: gtk_tree_selection_select_path: assertion 'path != NULL' failed
But otherwise this does not seem to indicate any trouble.
date: "2021-03-07 20:00:48" title: "Lesser Known Static Site Generators" slug: blog-2021-03-07-lesser-known-static-site-generators draft: false categories: ["Web"] tags: ["SSG"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Lesser Known Static Site Generators on eklausmeier.goip.de.
Well known static site generators are Hugo (written in Go), Pelican (written in Python), Grav (written in PHP), or Eleventy (written in JavaScript). For a list of static site generators see Jamstack (322 generators listed) or Static Site Generators (460 generators listed).
The following three static site generators unfortunately are not listed in before given Jamstack overview.
- mkws: a minimalist static site generator, written in 31 lines of sh and 400 lines of C
- Saaze: an easy to use generator which is able to generate static or dynamic sites, written in PHP/Symfony
- Franklin: easy embedding of math and Julia notebooks, written in Julia
To better understand what makes above list stand out against the more popular ones: Hugo's daily use is a little bit cumbersome and every release of Hugo gets more complex, additions to the Hugo source code are unwelcome.
1. mkws was covered in mkws - Static Site Generation With The Shell. The main loop in the 31 lines of shell code are:
for t in "$srcdir"/*.upphtml
do
echo "Making $(basename "${t%.upphtml}".html)"
pp "$sharedir"/l.upphtml "$t" "$1" > \
"$(basename "${t%.upphtml}".html)"
done
I.e., read files with suffix upphtml and run them through the simple pre-processor program pp. pp is like php, but way simpler, although not necessarily faster. pp pumps everything between #! lines through a shell.
Posts in mkws have to be written in HTML, unless you add another helper program to the equation. mkws is to be considered a proof-of-concept.
2. Saaze has been written by Gilbert Pellegrom, who also wrote PicoCMS. Directory layout of Saaze is as below:
saaze/
├── build/
├── cache/
├── content/
│ ├── pages/
│ | └── example-page.md
│ └── pages.yml
├── public/
│ └── index.php
└── templates/
├── collection.blade.php
├── entry.blade.php
├── error.blade.php
└── layout.blade.php
The "build" directory will contain all HTML files, if one generates entirely static pages with the command
php saaze build
The "public" directory is used, if instead, you want your pages fully dynamic, i.e., with possible PHP code embedded.
The "templates" directory is used for templates, which are based on Laravel Blade.
Posts in Saaze are written in Markdown, and each post is prepended with a short Yaml frontmatter header, e.g.,
---
title: An Example Post
date: "2020-10-13"
---
This is an **example** with some _markdown_ formatting.
Posts in Saaze are called "entries". These called "entries" are collected together in what Saaze calls "collection".
Saaze can be extended to match ones own Markdown tags. This is described in Extending Saaze.
3. Franklin is used for the entire Julia documentation and shines at mathematics. It was written by Thibaut Lienart. For example, the Julia web-site is generated by Franklin.
The directory structure of Franklin is:
.
├── _assets/
├── _layout/
├── _libs/
├── __site
│ ├── index.html
│ ├── folder
│ │ └── subpage
│ │ └── index.html
│ └── page
│ └── index.html
├── config.md
├── index.md
├── folder
│ └── subpage.md
└── page.md
The "__site" directory and its corresponding sub-folders are created by running
newsite("TestWebsite"; template="vela")
from within the Julia REPL. The "__site" directory is then to become the web-root of your web-presence.
From the three generators, Franklin is obviously the most powerful one. It has good integration to site-search using lunr.js, with math, with source code, even live Julia code, or plots.
Each post in Franklin is a plain Markdown file.
date: "2021-03-15 19:00:53" title: "Add Disjoint IP Addresses To SSHGuard Blacklist" slug: blog-2021-03-15-add-disjoint-ip-addresses-to-sshguard-blacklist draft: false categories: ["Linux", "network", "security"] tags: ["SSHGuard"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Add Disjoint IP Addresses To SSHGuard Blacklist on eklausmeier.goip.de.
Problem at hand: There are multiple machines running SSHGuard. Each of these machines accumulates different sets of blacklists. Task: Add disjoint IP addresses from one machine to another machine's blacklist.
1. Copy from "master" machine:
scp -p master:/var/db/sshguard/blacklist.db blacklist_master.db
This blacklist looks like this:
1615278352|100|4|59.46.169.194
1615278438|100|4|45.144.67.47
1615279294|100|4|122.155.47.9
1615279795|100|4|106.12.173.237
1615284110|100|4|103.152.79.161
1615284823|100|4|79.255.172.22
1615286299|100|4|106.12.171.76
The first entry is time in time_t format, second entry is service, in our case always 100=ssh, third entry is either 4 for IPv4, or 6 for IPv6, fourth entry is actual IP address, see Analysis And Usage of SSHGuard.
2. Create difference set: Run script sshgadd:
sshgadd /var/db/sshguard/blacklist.db blacklist_master.db
Script sshgadd is:
[ -z "$1" ] && exit 11
[ -z "$2" ] && exit 12
[ -f "$1" ] || exit 13
[ -f "$2" ] || exit 14
comm -23 <(cut -d\| -f4 $1 | sort) <(cut -d\| -f4 $2 | sort) \
| perl -ane 'print "1613412470|100|4|$_"'
The comm command can suppress common columns:
-1 suppress column 1 (lines unique to FILE1)
-2 suppress column 2 (lines unique to FILE2)
-3 suppress column 3 (lines that appear in both files)
This "<(list)" construct is called process substitution.
3. Stop SSHGuard on machine and add output of sshgadd to blacklist via any editor of your choice, or use cat and mv.
date: "2021-03-29 19:00:10" title: "PHP extension seg-faulting" slug: blog-2021-03-29-php-extension-seg-faulting draft: false categories: ["PHP", "programming"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from PHP extension seg-faulting on eklausmeier.goip.de.
Task at hand: Call Cobol (=GnuCobol) from PHP. I used FFI for this:
<?php
$cbl = FFI::cdef("int phpsqrt(void); void cob_init_nomain(int,char**); int cob_tidy(void);", "/srv/http/phpsqrt.so");
$ffj0 = FFI::cdef("double j0(double);", "libm.so.6");
$cbl->cob_init_nomain(0,null);
$ret = $cbl->phpsqrt();
printf("\tret = %d<br>\n",$ret);
echo "Before calling cob_tidy():<br>\n";
echo "\tReturn: ", $cbl->cob_tidy(), "<br>\n";
printf("j0(2) = %f<br>\n", $ffj0->j0(2));
?>
The Cobol program is:
000010 IDENTIFICATION DIVISION.
000020 PROGRAM-ID. phpsqrt.
000030 AUTHOR. Elmar Klausmeier.
000040 DATE-WRITTEN. 01-Jul-2004.
000050
000060 DATA DIVISION.
000070 WORKING-STORAGE SECTION.
000080 01 i PIC 9(5).
000090 01 s usage comp-2.
000100
000110 PROCEDURE DIVISION.
000120* DISPLAY "Hello World!".
000130 PERFORM VARYING i FROM 1 BY 1 UNTIL i > 10
000140 move function sqrt(i) to s
000150* DISPLAY i, " ", s
000160 END-PERFORM.
000170
000180 move 17 to return-code.
000190 GOBACK.
000200
Config in php.ini file has to be changed:
extension=ffi
ffi.enable=true
To call GnuCobol from C, you have to first call cob_init() or cob_init_nomain(), which initializes GnuCobol. I tried both initialization routines, and both resulted in PHP crashing after running above program, i.e., segmentation fault.
I created a bug for this: FFI crashes with segmentation fault when calling cob_init().
1. I compiled PHP 8.0.3 from source. For this I had to add below packages:
pacman -S tidy freetds c-client
I grep'ed my current configuration:
php -i | grep "Configure Comman"
Configure Command => './configure' '--srcdir=../php-8.0.3' '--config-cache' '--prefix=/usr' '--sbindir=/usr/bin' '--sysconfdir=/etc/php' '--localstatedir=/var' '--with-layout=GNU' '--with-config-file-path=/etc/php' '--with-config-file-scan-dir=/etc/php/conf.d' '--disable-rpath' '--mandir=/usr/share/man' '--enable-cgi' '--enable-fpm' '--with-fpm-systemd' '--with-fpm-acl' '--with-fpm-user=http' '--with-fpm-group=http' '--enable-embed=shared' '--enable-bcmath=shared' '--enable-calendar=shared' '--enable-dba=shared' '--enable-exif=shared' '--enable-ftp=shared' '--enable-gd=shared' '--enable-intl=shared' '--enable-mbstring' '--enable-pcntl' '--enable-shmop=shared' '--enable-soap=shared' '--enable-sockets=shared' '--enable-sysvmsg=shared' '--enable-sysvsem=shared' '--enable-sysvshm=shared' '--with-bz2=shared' '--with-curl=shared' '--with-db4=/usr' '--with-enchant=shared' '--with-external-gd' '--with-external-pcre' '--with-ffi=shared' '--with-gdbm' '--with-gettext=shared' '--with-gmp=shared' '--with-iconv=shared' '--with-imap-ssl' '--with-imap=shared' '--with-kerberos' '--with-ldap=shared' '--with-ldap-sasl' '--with-mhash' '--with-mysql-sock=/run/mysqld/mysqld.sock' '--with-mysqli=shared,mysqlnd' '--with-openssl' '--with-password-argon2' '--with-pdo-dblib=shared,/usr' '--with-pdo-mysql=shared,mysqlnd' '--with-pdo-odbc=shared,unixODBC,/usr' '--with-pdo-pgsql=shared' '--with-pdo-sqlite=shared' '--with-pgsql=shared' '--with-pspell=shared' '--with-readline' '--with-snmp=shared' '--with-sodium=shared' '--with-sqlite3=shared' '--with-tidy=shared' '--with-unixODBC=shared' '--with-xsl=shared' '--with-zip=shared' '--with-zlib'
To this I added --enable-debug. Command configure needs two minutes. Then make -j8 needs another two minutes.
I copied php.ini to local directory, changed it to activated FFI. Whenever I called
$BUILD/sapi/cli/php
I had to add -c php.ini, when I called an extension written by me, stored in ext/.
2. The fix for segmentation fault is actually pretty easy: Just set environment variable ZEND_DONT_UNLOAD_MODULES:
ZEND_DONT_UNLOAD_MODULES=1 $BUILD/sapi/cli/php -c php.ini -r 'test1();'
Reason for this: see valgrind output below.
3. Before I had figured out the "trick" with ZEND_DONT_UNLOAD_MODULES, I wrote a PHP extension. The extension is:
/* {{{ void test1() */
PHP_FUNCTION(test1)
{
ZEND_PARSE_PARAMETERS_NONE();
php_printf("test1(): The extension %s is loaded and working!\r\n", "callcob");
cob_init(0,NULL);
}
/* }}} */
Unfortunately, running this extension resulted in:
Module compiled with build ID=API20200930,NTS
PHP compiled with build ID=API20200930,NTS,debug
These options need to match
I solved this by adding below string:
/* {{{ callcob_module_entry */
zend_module_entry callcob_module_entry = {
STANDARD_MODULE_HEADER,
//sizeof(zend_module_entry), ZEND_MODULE_API_NO, 1, USING_ZTS,
"callcob", /* Extension name */
ext_functions, /* zend_function_entry */
NULL, /* PHP_MINIT - Module initialization */
NULL, /* PHP_MSHUTDOWN - Module shutdown */
PHP_RINIT(callcob), /* PHP_RINIT - Request initialization */
NULL, /* PHP_RSHUTDOWN - Request shutdown */
PHP_MINFO(callcob), /* PHP_MINFO - Module info */
PHP_CALLCOB_VERSION, /* Version */
STANDARD_MODULE_PROPERTIES
",debug"
};
/* }}} */
I guess this is not the recommend approach.
4. Valgrind shows the following:
==37350== Process terminating with default action of signal 11 (SIGSEGV): dumping core
==37350== Access not within mapped region at address 0x852AD20
==37350== at 0x852AD20: ???
==37350== by 0x556EF7F: ??? (in /usr/lib/libc-2.33.so)
==37350== by 0x5570DCC: getenv (in /usr/lib/libc-2.33.so)
==37350== by 0x76BB43: module_destructor (zend_API.c:2629)
==37350== by 0x75EE31: module_destructor_zval (zend.c:782)
==37350== by 0x7777A1: _zend_hash_del_el_ex (zend_hash.c:1330)
==37350== by 0x777880: _zend_hash_del_el (zend_hash.c:1353)
==37350== by 0x779188: zend_hash_graceful_reverse_destroy (zend_hash.c:1807)
==37350== by 0x769390: zend_destroy_modules (zend_API.c:1992)
==37350== by 0x75F582: zend_shutdown (zend.c:1078)
==37350== by 0x6C3F17: php_module_shutdown (main.c:2359)
==37350== by 0x84E46D: main (php_cli.c:1351)
==37350== If you believe this happened as a result of a stack
==37350== overflow in your program's main thread (unlikely but
==37350== possible), you can try to increase the size of the
==37350== main thread stack using the --main-stacksize= flag.
==37350== The main thread stack size used in this run was 8388608.
. . .
zsh: segmentation fault (core dumped) valgrind $BUILD/sapi/cli/php -c $BUILD/php.ini -r 'test1();'
As shown above, the relevant code in question is Zend/zend_API.c in line 2629. This is shown below:
void module_destructor(zend_module_entry *module) /* {{{ */
{
. . .
module->module_started=0;
if (module->type == MODULE_TEMPORARY && module->functions) {
zend_unregister_functions(module->functions, -1, NULL);
}
#if HAVE_LIBDL
if (module->handle && !getenv("ZEND_DONT_UNLOAD_MODULES")) {
DL_UNLOAD(module->handle);
}
#endif
}
/* }}} */
It is the DL_UNLOAD, which is a #define for dlclose, which actually provokes the crash.
According PHP Internals Book -- Zend Extensions:
Here, we are loaded as a PHP extension. Look at the hooks. When hitting MSHUTDOWN(), the engine runs our MSHUTDOWN(), but it unloads us just after that ! It calls for dlclose() on our extension, look at the source code, the solution is as often located in there. So what happens is easy, just after triggering our RSHUTDOWN(), the engine unloads our pib.so ; when it comes to call our Zend extension part shutdown(), we are not part of the process address space anymore, thus we badly crash the entire PHP process.
What is still not understood: Why does FFI not crash with those simple functions, like printf(), or sqrt()?
date: "2021-05-18 13:00:00" title: "Moved Blog To eklausmeier.goip.de" slug: blog-2021-05-18-moved-blog-to-eklausmeier-goip-de draft: false categories: ["WordPress"] tags: ["Saaze", "PHP", "Go"]
author: "Elmar Klausmeier"
This post was automatically copied from Moved Blog To eklausmeier.goip.de on eklausmeier.goip.de.
The blog eklausmeier.wordpress.com is no longer maintained. I moved to eklausmeier.goip.de, i.e., this one. During migration I corrected a couple of minor typos and dead links.
Main reasons for the move:
- This new WordPress editor put the last nail in the coffin, existing content is garbled once you edit it
- Math typesetting is quite arduous; I would like to have full MathJax support
- Overall slow
- Importing does not allow to overwrite posts, unless you delete everything first
Nevertheless, I started blogging in WordPress since January 2008, really used it starting in 2012. Collected more than 120 thousand views and almost 100 thousand visitors. One should not forget, in all fairness, that WordPress never charged me a dime.
Had WordPress not deleted the so called "Classical Editor", I would probably still be with WordPress. As expected the move from WordPress to this blog took quite some time as I had to migrate ca. 300 blog posts.
This blog is now powered by Saaze written by Gilbert Pellegrom. As of today it looks like that the Saaze website and this blog are the onliest websites using Saaze. Initially Gilbert Pellegrom also powered his blog with Saaze, but has since migrated away to Webflow. This keeps me puzzled about the long-term survival of Saaze.
I have already written on Saaze here: Lesser Known Static Site Generators.
I stumbled onto Saaze by accident. I initially took a look at Stati from Jonathan Foucher, who wrote about it in his blog post Stati, a PHP static site generator that works on any existing Jekyll site. Stati is Jekyll compatible. From there I got to Pico written by Gilbert Peegrom, and from there to Saaze.
Migration took me roughly one month. Of course, I didn't work on this full-time. But during the migration I did not write any new posts in WordPress. The steps in the migration were:
- Adapted
wp2hugo.gotowp2saaze.go, which converted WordPress XML export file to a set of Markdown files. - Wrote a Saaze extension, called
MathParser.php, to handle math, YouTube videos, Twitter tweets, etc. - Wrote
mkdwnrssPerl script to create an RSS feed from Markdown files.
The move away from WordPress was made easy, as I had previously checked on various static site generators and had closer contact with Hugo, for which I already wrote a converter, see Converting WordPress Export File to Hugo. Getting all search-and-replace strings right, getting the regular expressions right was the most time consuming. Writing an Saaze extension was pretty straightforward. I also played a little bit with the Laravel Blade templates, and with TailwindCSS.
Did the blog-move cure the above problems with WordPress?
- There is definitely no more automatic garbling of one's own content. Content is in pure Markdown. It is easier to write than the previous WordPress mix of HTML and pseudo-Markdown. This destruction of my content was the trigger point for me to say: "enough is enough". Editing is much more enjoyable with vi as using some browser-based editor with WordPress. In particular it is very easy to edit full-screen.
- Math typesetting with MathJax make things way easier. For example, I can now use
\eqalignagain. In WordPress I used some clumsy work-arounds for that. - During writing of new articles I run
php saaze serveand the pages are presented immediately. This is way faster than WordPress's "View" feature, which usually takes a few seconds to present the new post. Actual publishing/deploying as static content takes less than two seconds on an AMD Ryzen 5 PRO 3400G, max clocked with 3.7 GHz. - As all content is plain Markdown, with some Yaml-header, it can easily be saved, zipped, and moved. In particular, it can also easily be processed by scripts.
date: "2021-05-22 19:00:00" title: "Using GoAccess with Hiawatha Web-Server" slug: blog-2021-05-22-using-goaccess-with-hiawatha-web-server draft: false categories: ["www"] tags: ["Hiawatha", "GoAccess", "log"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Using GoAccess with Hiawatha Web-Server on eklausmeier.goip.de.
GoAccess is a remarkable analyzer for your log-files written by the web-server. For example, GoAccess can read and analyze the log-files from Apache web-server. In the same vein, after some configuration, it can also read and analyze the log-files from Hiawatha web-server. The Hiawatha web-server is used for this blog. I have written on Hiawatha here: Set-Up Hiawatha Web-Server, and Set-Up "Let's Encrypt" for Hiawatha Web-Server.
Below is the required configuration such that GoAccess can read Hiawatha log-files:
date-format %a %d %b %Y
time-format %T %z
log-format %h|%d %t|%s|%b|%r|%R|%u|Host: %v|%^|%^|%^|%^|%^|%^|%^|%^|%^|%^
This should be placed in file $HOME/.goaccessrc.
First go to the log-file directory: cd /var/log/hiawatha. Running goaccess is thus:
goaccess access.log
Usually you will have multiple log-files, the majority of which will be zipped. GoAccess can read from stdin, therefore you can feed the unzipped log-files to GoAccess. For example:
zcat access.*.gz | goaccess access.log access.log.1 > /srv/http/goaccess.html
The HTML output looks something like this for OS distribution:
 Overall info in HTML format looks like this:
Overall info in HTML format looks like this:
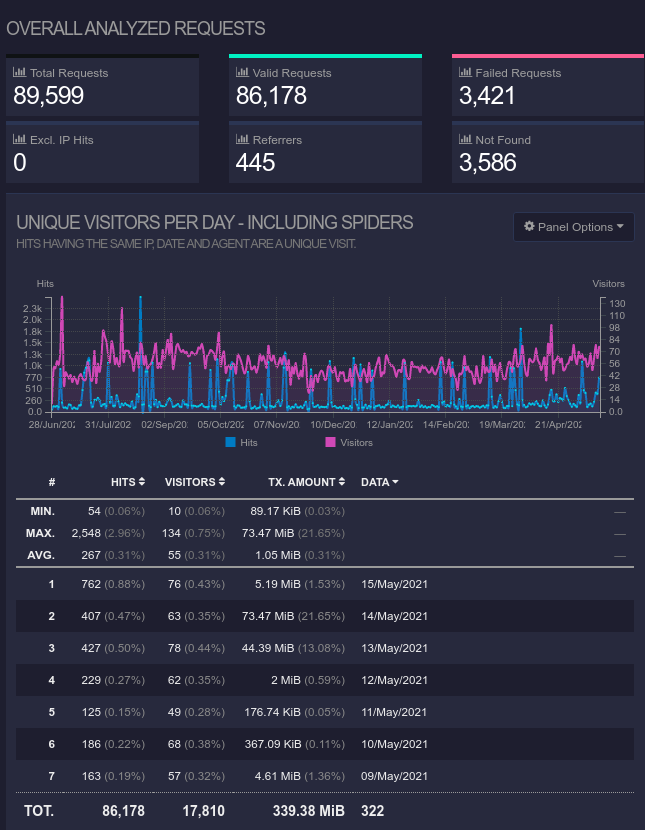 I was quite surprised how much traffic the web-server serves, even before this blog was hosted on Hiawatha. Much of this traffic seems to bots and junk.
I was quite surprised how much traffic the web-server serves, even before this blog was hosted on Hiawatha. Much of this traffic seems to bots and junk.
GoAccess can either produce HTML reports, or can show the results directly in your terminal. Below is the output from st or xterm:
Dashboard - Overall Analyzed Requests (09/May/2021 - 22/May/2021) [Active Panel: Requests]
Total Requests 10782 Unique Visitors 1031 Requested Files 1119 Referrers 199
Valid Requests 10576 Init. Proc. Time 1s Static Files 138 Log Size 3.40 MiB
Failed Requests 206 Excl. IP Hits 0 Not Found 2218 Tx. Amount 192.51 MiB
Log Source access.log; access.log.1
> 2 - Requested Files (URLs) Total: 366/1119
Hits h% Vis. v% Tx. Amount Mtd Proto Data
---- ------ ---- ------ ---------- ---- -------- ----
893 8.44% 589 57.13% 1.06 MiB GET HTTP/1.1 /
191 1.81% 155 15.03% 1.59 MiB GET HTTP/1.1 /blog/index.html
112 1.06% 16 1.55% 24.81 KiB HEAD HTTP/1.1 /
101 0.95% 16 1.55% 929.90 KiB POST HTTP/1.1 /build/search.php
68 0.64% 58 5.63% 557.15 KiB GET HTTP/1.1 /build/blog/index.html
54 0.51% 30 2.91% 186.07 KiB GET HTTP/1.1 /feed.xml
47 0.44% 6 0.58% 10.97 KiB HEAD HTTP/1.1 /blog/index.html
3 - Static Requests Total: 138/138
Hits h% Vis. v% Tx. Amount Mtd Proto Data
---- ------ ---- ------ ---------- ---- -------- ----
225 2.13% 83 8.05% 531.72 KiB GET HTTP/1.1 /favicon.ico
140 1.32% 133 12.90% 38.95 KiB GET HTTP/1.1 /robots.txt
10 0.09% 9 0.87% 168.17 KiB GET HTTP/1.1 /build/img/jpilot-plugin.png
10 0.09% 9 0.87% 593.29 KiB GET HTTP/1.1 /build/img/jpilot-search.png
8 0.08% 6 0.58% 1.67 KiB HEAD HTTP/1.0 /robots.txt
4 0.04% 2 0.19% 58.77 KiB GET HTTP/1.1 /img/PerfRyzenIntelARM1.png
4 0.04% 1 0.10% 2.03 MiB GET HTTP/1.1 /build/img/IMG_20140413_124816.jpg
4 - Not Found URLs (404s) Total: 366/2218
Hits h% Vis. v% Tx. Amount Mtd Proto Data
---- ------ ---- ------ ---------- ---- -------- ----
59 0.56% 0 0.00% 54.00 KiB GET HTTP/1.1 /wp-login.php
54 0.51% 0 0.00% 50.73 KiB GET HTTP/1.1 /phpmyadmin/
32 0.30% 0 0.00% 29.24 KiB POST HTTP/1.1 /vendor/phpunit/phpunit/src/Util/PHP/eval-stdin.php
30 0.28% 0 0.00% 28.18 KiB GET HTTP/1.1 /ads.txt
29 0.27% 0 0.00% 26.48 KiB GET HTTP/1.1 /vendor/phpunit/phpunit/src/Util/PHP/eval-stdin.php
27 0.26% 0 0.00% 25.26 KiB GET HTTP/1.1 /_ignition/execute-solution
23 0.22% 0 0.00% 21.50 KiB GET HTTP/1.1 /wp-content/plugins/wp-file-manager/readme.txt
5 - Visitor Hostnames and IPs Total: 366/830
[?] Help [Enter] Exp. Panel 0 - Sat May 22 18:41:56 2021 [q]uit GoAccess 1.4.6
Pressing Tab-key will navigate through the various panels.
There is a short mentioning in Wikipedia as well: GoAccess. The man-page provides a wealth of information.
date: "2021-05-23 20:00:00" title: "Speed-Tests With Pingdom.com" slug: blog-2021-05-23-speed-tests-with-pingdom-com draft: false categories: ["www"] tags: ["speed", "pingdom.com"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Speed-Tests With Pingdom.com on eklausmeier.goip.de.
As I have moved my blog from WordPress to eklausmeier.goip.de, I wanted to know if I am really getting better response times across the globe. WordPress always felt slow. Below measurements will confirm this.
Pingdom.com is a monitoring and performance measurement website. See Wiki article.
Let's start with the gold-standard, i.e., let's first check how fast Google search page is when loaded from San Franzisco:
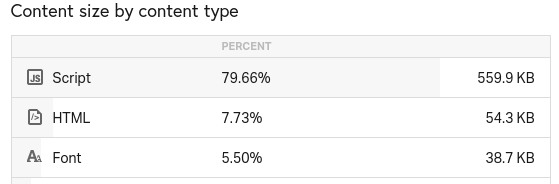
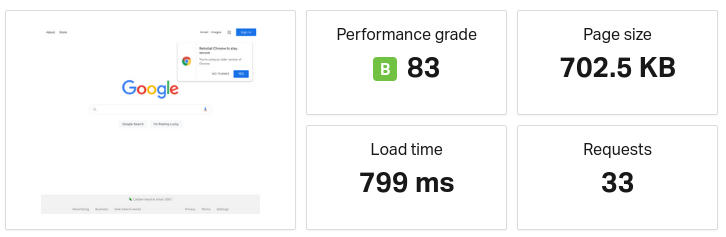 Load time is 799ms. Performance grade is 83. Load time and performance grade is the same if fetched from Washington D.C. Below image shows that Google's page contains more than half a megabyte of Javascript, and it contains ca. 50 KB of HTML.
Load time is 799ms. Performance grade is 83. Load time and performance grade is the same if fetched from Washington D.C. Below image shows that Google's page contains more than half a megabyte of Javascript, and it contains ca. 50 KB of HTML.
A only-text page of my blog: Moved Blog To eklausmeier.goip.de fetched from Washington D.C.:
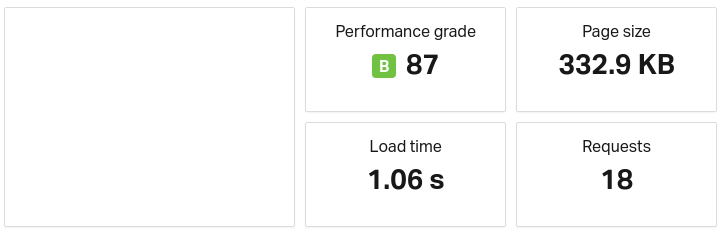 Load time is 1,060ms. Performance grade is 87, i.e., better than Google's. For this article the skewness between CSS and HTML is very striking. CSS is 250 KB compared to 4 KB of HTML. See below image.
Load time is 1,060ms. Performance grade is 87, i.e., better than Google's. For this article the skewness between CSS and HTML is very striking. CSS is 250 KB compared to 4 KB of HTML. See below image.
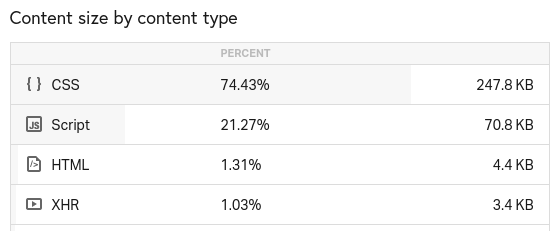 Obviously this blog needs a diet regarding CSS. The ratio is just too bad.
Obviously this blog needs a diet regarding CSS. The ratio is just too bad.
A post with images from my blog: Using GoAccess with Hiawatha Web-Server fetched from Washington D.C.:
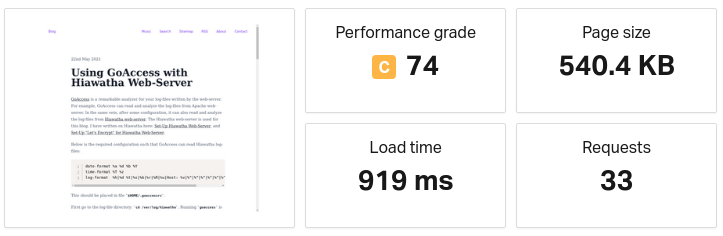 Load time is 919ms. Performance grade is 74.
Load time is 919ms. Performance grade is 74.
A very small text-only post in WordPress: Moved Blog To eklausmeier.goip.de fetched from Washington D.C.:
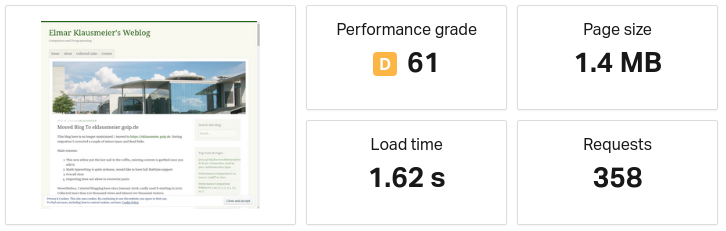 Load time is 1,620ms. This blog post is smaller than the almost same blog post on my blog. In fairness to WordPress, WordPress shows images, more references, more buttons for this page.
Load time is 1,620ms. This blog post is smaller than the almost same blog post on my blog. In fairness to WordPress, WordPress shows images, more references, more buttons for this page.
These results in comparison to Google are quite astounding as my upload speed is just 50 MBit/s, i.e., this is the speed with which visitors can download content from my web-server. Also, I use no CDN.
date: "2021-05-29 20:00:00" title: "Configure Lighttpd With PHP and HTTPS" slug: blog-2021-05-29-configure-lighttpd-with-php-and-https draft: false categories: ["www"] tags: ["web-server", "lighttpd"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Configure Lighttpd With PHP and HTTPS on eklausmeier.goip.de.
I use the Hiawatha web-server on my servers. For example, this blog runs on Hiawatha. Recently I needed a web-server on Red Hat Enterprise. Unfortunately, Red Hat does not provide Hiawatha directly on its Satellite program, but Lighttpd was there. I also wanted to use PHP and the connection should be secure, i.e., I needed https.
I had written on the lines of code for Apache, Lighttpd, NGINX, and Hiawatha here: Set-Up Hiawatha Web-Server.
Below is the required config file for Lighttpd:
# See /usr/share/doc/lighttpd
# and http://redmine.lighttpd.net/projects/lighttpd/wiki/Docs:ConfigurationOptions
server.port = 8080
server.username = "http"
server.groupname = "http"
server.document-root = "/srv/http"
server.errorlog = "/var/log/lighttpd/error.log"
dir-listing.activate = "enable"
index-file.names = ( "index.html", "index.php" )
mimetype.assign = (
".html" => "text/html",
".txt" => "text/plain",
".css" => "text/css",
".js" => "application/x-javascript",
".jpg" => "image/jpeg",
".jpeg" => "image/jpeg",
".gif" => "image/gif",
".png" => "image/png",
"" => "application/octet-stream"
)
#
# which extensions should not be handle via static-file transfer
#
# .php, .pl, .fcgi are most often handled by mod_fastcgi or mod_cgi
#
static-file.exclude-extensions = ( ".php", ".pl", ".fcgi", ".scgi" )
server.modules += ( "mod_openssl", "mod_status", "mod_fastcgi" )
status.config-url = "/config"
status.statistics-url = "/statistics"
$SERVER["socket"] == ":8443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/hiawatha/eklausmeier.goip.de.pem"
}
fastcgi.server = ( ".php" =>
( "php-local" =>
(
"socket" => "/tmp/php-fastcgi-1.socket",
"bin-path" => "/bin/php-cgi",
"max-procs" => 1,
"broken-scriptfilename" => "enable",
),
"php-num-procs" =>
(
"socket" => "/tmp/php-fastcgi-2.socket",
"bin-path" => "/bin/php-cgi",
"bin-environment" => (
"PHP_FCGI_CHILDREN" => "1",
"PHP_FCGI_MAX_REQUESTS" => "10000",
),
"max-procs" => 5,
"broken-scriptfilename" => "enable",
),
),
)
As I already run Hiawatha, the ports 80 and 443 are in use, so I switched to 8080 and 8443 instead. I re-use the certificate for Hiawatha, i.e., the PEM-file.
Processes are as follows:
$ ps -ef | grep lighttpd
root 154125 1 0 12:30 ? 00:00:00 /usr/bin/lighttpd-angel -D -f /etc/lighttpd/lighttpd.conf
http 154126 154125 0 12:30 ? 00:00:00 /usr/bin/lighttpd -D -f /etc/lighttpd/lighttpd.conf
date: "2021-05-30 20:00:00" title: "Generate RSS from Markdown" slug: blog-2021-05-30-generate-rss-from-markdown draft: false categories: ["www"] tags: ["RSS", "feed", "Markdown"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Generate RSS from Markdown on eklausmeier.goip.de.
For this blog I wanted an RSS feed. Saaze by default does not provide this functionality. Saaze is supposed to be "stupidly simple" by design, which I consider a plus.
Luckily, generating an RSS feed is simple. It contains a header with some fixed XML. Then each post, is printed as so called "item" with
- link / URL
- publication date
- title
- an excerpt or even the full blog post
Finally the required closing XML tags. That's it.
Taking this information directly from Markdown file with some frontmatter seems to be the easiest approach. For example, the frontmatter for this blog post is:
---
date: "2021-05-30 20:00:00"
title: "Generate RSS from Markdown"
draft: false
categories: ["www"]
tags: ["RSS", "feed", "Markdown"]
author: "Elmar Klausmeier"
prismjs: true
---
Below Perl script mkdwnrss implements this. As input files it wants those blog posts which should be part of the RSS feed. So usually you will "generate" the list of files. Implementing this in PHP would be equally simple.
The excerpt is restricted to either 9 lines of Markdown or less than 500 characters.
#!/bin/perl -W
# Create RSS XML file ("feed") based on Markdown files
#
# Input: List of Markdown files (order of files determines order of <item>))
# Output: RSS (description with 3 lines of Markdown as excerpt)
#
# Example:
# mkdwnrss `find blog/2021 -type f | sort -r`
use strict;
my $dt = localtime();
print <<"EOT";
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<title>Elmar Klausmeier's Blog</title>
<description>Elmar Klausmeier's Blog</description>
<lastBuildDate>$dt</lastBuildDate>
<link>https://eklausmeier.goip.de</link>
<atom:link href="https://eklausmeier.goip.de/feed.xml" rel="self" type="application/rss+xml" />
<generator>mkdwnrss</generator>
EOT
sub item(@) {
my $f = $_[0];
open(F,"< $f") || die("Cannot open $f");
my $link = $f;
$link =~ s/\.md$/\//;
print "\t<item>\n"
. "\t\t<link>https://eklausmeier.goip.de/$link</link>\n"
. "\t\t<guid>https://eklausmeier.goip.de/$link</guid>\n";
my ($sep,$linecnt,$excerpt) = (0,0,"");
while (<F>) {
chomp;
if (/^\-\-\-$/) { $sep++ ; next; }
if ($sep == 1) {
if (/^title:\s+"(.+)"$/) {
printf("\t\t<title>%s</title>\n",$1);
} elsif (/^date:\s+"(.+)"$/) {
printf("\t\t<pubDate>%s</pubDate>\n",$1);
}
} elsif ($sep >= 2) {
next if (length($_) == 0);
if ($linecnt++ == 0) {
print "\t\t<description><![CDATA[";
$excerpt = $_;
} elsif ($linecnt < 9 || length($excerpt) < 500) {
$excerpt .= " " . $_;
} else {
last;
}
}
}
print $excerpt . "]]></description>\n" if ($linecnt > 0);
print "\t</item>\n";
close(F) || die("Cannot close $f");
}
while (<@ARGV>) {
item($_);
}
print "</channel>\n</rss>\n";
Source code for mkdwnrss is in GitHub.
During development I checked whether my RSS looks similar to the RSS feed in WordPress: feed. I also checked Alex Le's blog post on RSS feed: Create An RSS Feed From Scratch.
Added 08-Jul-2021: When checking the RSS in W3C Feed Validation Service the dates and descriptions were marked as non-compliant. This is now corrected. Checking now gives:

date: "2021-06-03 20:00:00" title: "Matomo with Hiawatha" slug: blog-2021-06-03-matomo-with-hiawatha draft: false categories: ["www"] tags: ["Matomo", "Hiawatha" ] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Matomo with Hiawatha on eklausmeier.goip.de.
For this blog I use the Hiawatha web-server. I wanted to employ a web-analysis tool. For this I chose Matomo). Matomo was called Piwik previously. I already use GoAccess on which I have written in Using GoAccess with Hiawatha Web-Server.
To use Matomo with Hiawatha I had to do the following:
- Unzip the matomo.zip file downloaded from Matomo latest
chown -R http:httpthe unzipped directory- Edit
index.phpin the matomo directory and addumask(022)directly after<?at the top of the file
Editing index.php will result in below warning, which can be ignored:
Errors below may be due to a partial or failed upload of Matomo files.
--> Try to reupload all the Matomo files in BINARY mode. <--
File size mismatch: /srv/http/matomo/index.php (expected length: 712, found: 724)
Point 3 clearly is non-obvious. First I didn't get any further with the installation of Matomo, as Matomo could not create directories. Even when I tried to chmod the directories properly, the new directory had wrong permission and no sub-directories could be created. To verifiy that it was indeed a specific Hiawatha problem with umask I ran:
<html>
<body>
<pre>
<?php
printf("umask() = %o\n", umask());
printf("umask() = %o\n", umask(0));
printf("umask() = %o\n", umask(0));
?>
</pre>
</body>
</html>
This confirmed:
umask() = 117
umask() = 117
umask() = 0
Now the question emerged, from where this silly umask came from. Looking at the source code showed that in hiawatha.c indeed set the umask:
int run_webserver(t_settings *settings) {
. . .
/* Misc settings
*/
tzset();
clearenv();
umask(0117);
date: "2021-06-05 21:00:03" title: "Using NUC as WLAN Router" slug: blog-2021-06-05-using-nuc-as-wlan-router draft: false categories: ["Linux", "network"] tags: ["iptables", "nuc", "router", "firewall", "sysctl", "NAT"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Using NUC as WLAN Router on eklausmeier.goip.de.
I had already written about setting up an Odroid as IP router: Using Odroid as IP router.
Today I powered down my second Odroid, which I had previously used as WLAN router. There was nothing wrong with the Odroid. It just drew 7W and the NUC was already running next to the Odroid. So there was no real reason for another machine. What is described here applies to any PC, it is not specific to an Intel NUC.
Here are the steps for the setup on Arch Linux.
1. Installing required WLAN driver. I had to install rtl8812au-dkms-git from AUR.
2. Set IP addresses. The WLAN card has to be set to a fixed IP address. I use systemd network for this. The first two files set the good old network names based on the MAC.
/etc/systemd/network: cat 00-eth0.link
[Match]
MACAddress=c0:3f:d5:61:e7:25
[Link]
Name=eth0
/etc/systemd/network: cat 00-wg0.link
[Match]
MACAddress=24:05:0f:f6:f7:2d
[Link]
Name=wg0
Now we set the actual IP addresses.
/etc/systemd/network: cat eth0.network
[Match]
Name=eth0
[Network]
Address=192.168.178.24/24
Gateway=192.168.178.1
DNS=192.168.178.1 8.8.8.8 1.1.1.1
/etc/systemd/network: cat wg0.network
[Match]
Name=wg0
[Network]
#DHCP=yes
Address=192.168.4.1/24
Gateway=192.168.178.1
DNS=192.168.178.1
3. Installing dnsmasq. Install dnsmasq. The dnsmasq configuration is as follows:
dhcp-range=192.168.4.51,192.168.4.99,255.255.255.0,12h
dhcp-host=e8:d8:d1:02:7c:5e,hp3830,192.168.4.16,12h
dhcp-host=94:65:2d:7a:c6:36,five,192.168.4.118,12h
dhcp-host=8c:83:e1:1c:25:d2,samsung,192.168.4.119,12h
dhcp-host=52:d4:94:59:d6:ce,tablet,192.168.4.120,12h
address=/ads.t-online.de/127.0.0.1
address=/adtech.de/127.0.0.1
address=/doubleclick.net/127.0.0.1
address=/adclick.g.doubleclick.net/127.0.0.1
It sets the IP range, fixes IP address for some devices so that these special devices get fixed IP addresses, maps some annoying web-site to localhost.
4. Checking forwarding. A router must be able to forward IP packets from one netword to another. You must have net.ipv4.ip_forward set via sysctl.
/etc/sysctl.d: cat 10-network.conf
# Enable IP forwarding
net.ipv4.ip_forward=1
4. Install access point. Install hostapd. Configuration is as below:
# Taken from https://wiki.archlinux.org/index.php/Software_access_point
# klm, 26-Aug-2018
interface=wg0
#bridge=br0
# SSID to be used in IEEE 802.11 management frames
ssid=<Your ESSID>
# Driver interface type (hostap/wired/none/nl80211/bsd)
driver=nl80211
# Country code (ISO/IEC 3166-1)
country_code=de
# Enable IEEE 802.11d. This advertises the country_code and the set of allowed
# channels and transmit power levels based on the regulatory limits. The
# country_code setting must be configured with the correct country for
# IEEE 802.11d functions.
# (default: 0 = disabled)
ieee80211d=1
# Operation mode (a = IEEE 802.11a (5 GHz), b = IEEE 802.11b (2.4 GHz),
# g = IEEE 802.11g (2.4 GHz), ad = IEEE 802.11ad (60 GHz); a/g options are used
# with IEEE 802.11n (HT), too, to specify band). For IEEE 802.11ac (VHT), this
# needs to be set to hw_mode=a. When using ACS (see channel parameter), a
# special value "any" can be used to indicate that any support band can be used.
# This special case is currently supported only with drivers with which
# offloaded ACS is used.
# Default: IEEE 802.11b
hw_mode=g
#new: hw_mode=a
# Channel number
channel=13
#new: channel=48
# Maximum number of stations allowed
max_num_sta=15
# Bit field: bit0 = WPA, bit1 = WPA2
wpa=2
# Bit field: 1=wpa, 2=wep, 3=both
auth_algs=1
# Set of accepted cipher suites
wpa_pairwise=CCMP
rsn_pairwise=CCMP
# Set of accepted key management algorithms
#wpa_key_mgmt=WPA-PSK WPA-PSK-SHA256
wpa_key_mgmt=WPA-PSK
wpa_passphrase=<Your WLAN password>
# hostapd event logger configuration
logger_stdout=-1
logger_stdout_level=2
# ieee80211n: Whether IEEE 802.11n (HT) is enabled
# 0 = disabled (default)
# 1 = enabled
# Note: You will also need to enable WMM for full HT functionality.
# Note: hw_mode=g (2.4 GHz) and hw_mode=a (5 GHz) is used to specify the band.
ieee80211d=1 # Advertise allowed channels and power
ieee80211n=1
ieee80211ac=1
Enable hostapd service via
systemctl enable hostapd
systemctl start hostapd
Checking WiFi can be done like so:
$ iwlist wg0 scan
wg0 Scan completed :
Cell 01 - Address: 34:31:C4:64:E5:91
ESSID:"Turk Telekom"
Protocol:IEEE 802.11bgn
Mode:Master
Frequency:2.412 GHz (Channel 1)
Encryption key:on
Bit Rates:144 Mb/s
Extra:rsn_ie=30140100000fac040100000fac040100000fac020000
IE: IEEE 802.11i/WPA2 Version 1
Group Cipher : CCMP
Pairwise Ciphers (1) : CCMP
Authentication Suites (1) : PSK
IE: Unknown: DD6F0050F204104A0001101044000102103B000103104700102C5A66C569964D595C0E3431C464E5911021000341564D1023000446
426F78102400043030303010420004303030301054000800060050F20400011011000446426F78100800020280103C0001031049000600372A000120
Quality=84/100 Signal level=10/100
Extra:fm=0003
Cell 02 - Address: 94:4A:0C:7E:1D:CB
ESSID:"WLAN-296708"
Protocol:IEEE 802.11bgn
Mode:Master
Frequency:2.412 GHz (Channel 1)
Encryption key:on
Bit Rates:144 Mb/s
Extra:rsn_ie=30140100000fac040100000fac040100000fac020c00
IE: IEEE 802.11i/WPA2 Version 1
Group Cipher : CCMP
Pairwise Ciphers (1) : CCMP
Authentication Suites (1) : PSK
IE: Unknown: DD800050F204104A0001101044000102103B000103104700102A5E35610C22E96D12CB27C8D718E0611021000842726F6164636F6D
1023000842726F6164636F6D1024000631323334353610420004313233341054000800060050F20400011011000A42726F6164636F6D4150100800020106103C00010110490
00600372A000120
Quality=100/100 Signal level=8/100
Extra:fm=0003
. . .
5. Activate NAT/Masquerading. Up to this point your smartphones and tablets can communicate with all other PCs in your network. But they cannot make any connections to the "real" internet. To activate this you must have iptables installed. Configuration of iptables in /etc/iptables/iptables.conf is thus:
*nat
-A POSTROUTING -o eth0 -j MASQUERADE
COMMIT
Very likely you want to single out some wireless devices which you want to connect to. Therefore you would add to the above nat table:
-A PREROUTING -i eth0 -p tcp -m tcp --dport 2223 -j DNAT --to-destination 192.168.4.118:2223
-A PREROUTING -i eth0 -p tcp -m tcp --dport 2224 -j DNAT --to-destination 192.168.4.119:2224
-A PREROUTING -i eth0 -p tcp -m tcp --dport 2225 -j DNAT --to-destination 192.168.4.120:2225
-A PREROUTING -i eth0 -p tcp -m tcp --dport 2226 -j DNAT --to-destination 192.168.4.146:2226
date: "2021-06-13 21:00:03" title: "Ampersands in Markdown URLs" slug: blog-2021-06-13-ampersands-in-markdown-urls draft: false categories: ["www"] tags: ["Markdown", "ampersand"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Ampersands in Markdown URLs on eklausmeier.goip.de.
In this blog I reference web-page- or image-URLs, which contain ampersands ("&"). For example, https://www.amazon.com/s?k=Richard+Stevens&ref=nb_sb_noss. Unfortunately, Markdown as specified by John Gruber does not allow this. This can be checked with John Gruber's "dingus" web-form.
So official Markdown when confronted with
abc [uvw](../iop&a) xyz
using "dingus" results in
<p>abc <a href="../iop&a">uvw</a> xyz</p>
I consider this to be an error. On 12-May-2021 I wrote an e-mail to John Gruber, but didn't receive any reply up to today. So apparently he won't fix it.
So to use ampersands, I had to add a special rule to the Saaze extension MathParser to not destroy ampersands. The logic is as follows:
private function amplink($html) {
$begintag = array(" href=\"http", " src=\"http");
$i = 0;
foreach($begintag as $tag) {
$last = 0;
for(;;) {
$start = strpos($html,$tag,$last);
if ($start === false) break;
$last = $start + 10;
$end = strpos($html,"\"",$last);
if ($end === false) break;
$link = substr($html,$start,$end-$start);
$link = str_replace("&","&",$link);
$html = substr_replace($html, $link, $start, $end-$start);
++$i;
}
}
//printf("\t\tamplink() changed %d times\n",$i);
return $html;
}
The PHP program has to handle href= and src= cases.
date: "2021-06-21 21:00:03" title: "WordPress.com Bulk Update" slug: blog-2021-06-21-wordpress-com-bulk-update draft: false categories: ["www"] tags: ["WordPress.com", "bulk"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from WordPress.com Bulk Update on eklausmeier.goip.de.
I wanted to redirect Google search results from WordPress.com to this blog. Ideally, one would add a "canonical link" in the head-tag of the HTML code. See for example stitcher.io: 07 – Be Searchable:
<head>
. . .
<link rel="canonical" href="https://stitcher.io/blogs-for-devs/07-be-searchable"/>
</head>
Unfortunately, WordPress.com does not allow this.
Next option was to add a link to each post in WordPress.com. WordPress.com now intentionally makes it difficult to conduct bulk-updates. You are forced to manually delete each post individually. For 300 posts in my case, I had to click two times each, i.e., 600 times:
- Select the post
- Click "Trash"
To make the whole process even more awkward, WordPress.com now adds annoying pop-ups for each deletion. Obviously, this reinforces that leaving WordPress.com was the right decision and was overdue. Sad to see that WordPress.com is getting worse.
So the process to edit each posts via script was:
- Download export file
- Manually delete all posts -- quite tedious
- Run script on export file
- Import export file again into WordPress.com
I used below simple Perl script to add a reference to this blog:
#!/bin/perl -W
# Insert link to eklausmeier.goip.de into each blog-post in WordPress export file
use strict;
my ($inItem,$year,$month,$day,$title) = (0,0,0,0,"");
while (<>) {
if (/^\s+<item>$/) { $inItem = 1; }
elsif ($inItem == 1 && /<link>https:\/\/eklausmeier.wordpress.com\/(\d{4})\/(\d\d)\/(\d\d)\/([\w\-]+)/) {
($year,$month,$day,$title) = ($1,$2,$3,$4);
#printf("\tlink: y=%s, m=%s, d=%s, t=%s\n",$year,$month,$day,$title);
$inItem = 2;
} elsif ($inItem == 2 && /^\s+<content:encoded><!\[CDATA\[(..)/) {
if ($1 ne "]]") {
my $url = "eklausmeier.goip.de/blog/$year/$month-$day-$title";
my $moved = "This post has moved to <a href=https://$url>$url</a>.\n\n";
s/^\s+<content:encoded><!\[CDATA\[/\t\t<content:encoded><!\[CDATA\[$moved/;
}
} elsif (/^\s+<\/item>$/) { $inItem = 0; }
print;
}
So in this script I search for the <item> tag, then search for the <link> tag, finally I search for <content:encoded>. Then I simply insert the correct URL to this blog.
date: "2021-06-27 21:00:00" title: "Deletion Troublesome in Hashnode.com" slug: blog-2021-06-27-deletion-troublesome-in-hashnode-com draft: false categories: ["www"] tags: ["Hashnode.com", "delete", "import"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Deletion Troublesome in Hashnode.com on eklausmeier.goip.de.
Before I moved away my blog from WordPress.com to this place, I checked whether another provider would fit my needs. See for example surge.sh, vercel.app, or netlify.app. I also looked at Hashnode.com. I liked Hashnode as it provides Markdown as input. I later learned that Hashnode also provided MathJax support. I didn't notice MathJax support in the first place, although it is clearly written in the help manual when you edit a post. Although it comes at the very end, after all the usual Markdown lecturing.
As an experiment before I imported all my Markdown posts into Hashnode, I just picked a single post and imported it into Hashnode. In contrast to Saaze, which this blog uses, Hashnode needs a slug entry in frontmatter, which contains the pathname of the URL. The import file is just a zip-file with Markdown files. After you import your zip-file, you have to press a "Publish" button. This went fine so far.
This is how a valid-for-import Markdown with frontmatter looks like:
---
slug: "blog-2021-06-21-wordpress-com-bulk-update"
date: "2021-06-21 21:00:03"
title: "WordPress.com Bulk Update"
draft: false
categories: ["www"]
tags: ["WordPress.com", "bulk"]
author: "Elmar Klausmeier"
prismjs: true
---
This post is originally from [WordPress.com Bulk Update](https://eklausmeier.goip.de/blog/2021/06-21-wordpress-com-bulk-update) on [eklausmeier.goip.de](https://eklausmeier.goip.de/blog).
After importing, I deleted the post manually in Hashnode. Then I re-imported the same file. This time the post was marked as already published, but wasn't. Clearly something was wrong here. Next, I changed the slug in the frontmatter of the Markdown file, zipped it, imported again. This time the post was published again after pressing the "Publish" button.
Next, I did the same entirely manually. I created a post on the Hashnode website. I then deleted it. I then created a post again with the same slug. I noticed that Hashnode had already changed the slug and append -1 after it. I changed the slug, but that didn't change anything.
So, Hashnode has a problem with deleting posts and re-using the same slug. This means, once slugs are used, they cannot be re-used. For importing corrected posts this is quite annoying.
I reported this problem on the support channel in Discord and got below reply:
sandeep – 06/28/2021 Thanks, we'll take a look and send a fix. cc @anand_1.0
That's an answer from Sandeep Panda, the co-founder of Hashnode. Quite remarkable.
date: "2021-06-29 17:00:00" title: "Brave Browser SIGSEGV Crash" slug: blog-2021-06-29-brave-browser-sigsegv-crash draft: false categories: ["www"] tags: ["Brave", "crash"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Brave Browser SIGSEGV Crash on eklausmeier.goip.de.
Today I saw a SIGSEGV error when fetching data from Twitter: 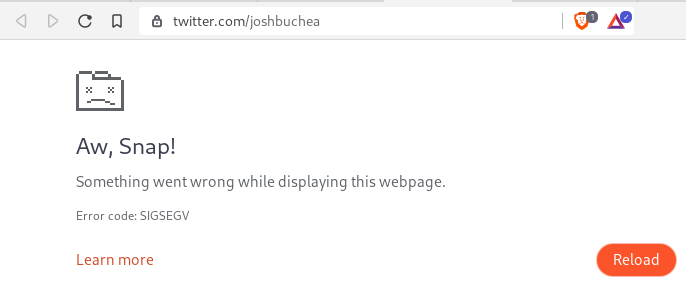
After reloading the page the error was gone. I hadn't seen this kind of error before.
Version used: Brave 1.25.73, Chromium: 91.0.4472.106 (Official Build) (64-bit). Revision 574f7b38e4e7244c92c4675e902e8f8e3d299ea7-refs/branch-heads/4472@{#1477}.
date: "2021-07-11 21:00:00" title: "Calling MD4C from PHP via FFI" slug: blog-2021-07-11-calling-md4c-from-php-via-ffi draft: false categories: ["Programming"] tags: ["PHP", "C", "Markdown"] author: "Elmar Klausmeier"
prismjs: true
This post was automatically copied from Calling MD4C from PHP via FFI on eklausmeier.goip.de.
1. Problem statement. When using one of the static-site generators an important part of all of them is to convert Markdown to HTML. In my case I use Saaze, and I measured roughly 60% of the runtime is used for converting Markdown to HTML. I have written on Saaze here and here. When converting my roughly 320 posts it took two seconds. When my machine is fully loaded with other computations, for example astrophysical computations, then converting to static takes four seconds. Of that total runtime more than 60% were only located in the toHtml() routine.
PHP 8 offers FFI, Foreign Function Interface. It was inspired by LauJIT FFI. PHP FFI is a very easy to use interface to C routines, authored by Dmitry Stogov. Although writing a PHP extension is quite easy, calling C routines via FFI is dead-simple. Hence, it was natural to substitute the toHtml() in PHP with MD4C.
2. C library. MD4C is a C library and auxiliary stand-alone executable to convert Markdown to HTML. It was written by Martin Mitas. It is installed on many Linux distributions by default, as it is used in Qt. MD4C is very fast. It is faster than cmark. In many cases it is 2-5 times faster than cmark. See Why is MD4C so fast?.
| Test name | Simple input | MD4C (seconds) | Cmark (seconds) |
| cmark-benchinput.md | (benchmark from CMark) | 0.3650 | 0.7060 |
| long-block-multiline.md | "foo\n" * 1000000 | 0.0400 | 0.2300 |
| long-block-oneline.md | "foo " 10 1000000 | 0.0700 | 0.1000 |
| many-atx-headers.md | "###### foo\n" * 1000000 | 0.0900 | 0.4670 |
| many-blanks.md | "\n" 10 1000000 | 0.0700 | 0.3110 |
| many-emphasis.md | "foo " * 1000000 | 0.1100 | 0.8460 |
| many-fenced-code-blocks.md | "~\nfoo\n~\n\n" * 1000000 | 0.1600 | 0.4010 |
| many-links.md | "a " * 1000000 | 0.2100 | 0.5110 |
| many-paragraphs.md | "foo\n\n" * 1000000 | 0.0900 | 0.4860 |
Here is another speed comparison between cmark, md4c and commonmark.js:
| Implementation | Time (sec) |
| commonmark.js | 0.59 |
| cmark | 0.12 |
| md4c | 0.04 |
3. PHP and C code. The code to be called instead of toHtml is therefore:
$ffi = FFI::cdef("char *md4c_toHtml(const char*);","/srv/http/php_md4c_toHtml.so");
$html = FFI::string( $ffi->md4c_toHtml($markdown) );
For testing the call to md4c_toHtml() use below PHP program with a Markdown file as first argument:
<?php
$ffi = FFI::cdef("char *md4c_toHtml(const char*);","/srv/http/php_md4c_toHtml.so");
printf("argv1 = %s\n", $argv[1]);
$markdown = file_get_contents($argv[1]);
$html = FFI::string( $ffi->md4c_toHtml($markdown) );
printf("%s", $html);
The routine md4c_toHtml() is:
/* Provide md4c to PHP via FFI
Copied many portions from Martin Mitas:
https://github.com/mity/md4c/blob/master/md2html/md2html.c
Compile like this:
cc -fPIC -Wall -O2 -shared php_md4c_toHtml.c -o php_md4c_toHtml.so -lmd4c-html
This routine is not thread-safe. For threading we either need a thread-id passed
or using a mutex to guard the static/global mbuf.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <md4c-html.h>
struct membuffer {
char* data;
size_t asize;
size_t size;
};
static void membuf_init(struct membuffer* buf, MD_SIZE new_asize) {
buf->size = 0;
buf->asize = new_asize;
if ((buf->data = malloc(buf->asize)) == NULL) {
fprintf(stderr, "membuf_init: malloc() failed.\n");
exit(1);
}
}
static void membuf_grow(struct membuffer* buf, size_t new_asize) {
buf->data = realloc(buf->data, new_asize);
if(buf->data == NULL) {
fprintf(stderr, "membuf_grow: realloc() failed.\n");
exit(1);
}
buf->asize = new_asize;
}
static void membuf_append(struct membuffer* buf, const char* data, MD_SIZE size) {
if(buf->asize < buf->size + size)
membuf_grow(buf, buf->size + buf->size / 2 + size);
memcpy(buf->data + buf->size, data, size);
buf->size += size;
}
static void process_output(const MD_CHAR* text, MD_SIZE size, void* userdata) {
membuf_append((struct membuffer*) userdata, text, size);
}
static struct membuffer mbuf = { NULL, 0, 0 };
char *md4c_toHtml(const char *markdown) { // return HTML string
int ret;
if (mbuf.asize == 0) membuf_init(&mbuf,65536);
mbuf.size = 0; // prepare for next call
ret = md_html(markdown,strlen(markdown),process_output,&mbuf,MD_DIALECT_GITHUB,0);
membuf_append(&mbuf,"\0",1); // make it a null-terminated C string, so PHP can deduce length
if (ret < 0) return "<br>- - - Error in Markdown - - -<br>\n";
return mbuf.data;
}
3. Application range. Any PHP based static-site generator would therefore profit if it simply used MD4C. But also any PHP based CMS employing Markdown. For a list of generators see Jamstack.
- Jigsaw, based on Blade templates like Saaze
- Statamic, commercial license
- Stati by Jonathan Foucher, Jekyll compatible
- Saaze
- Pico CMS, flat file CMS using Twig templates, not a static site generator
4. Benchmarks. Benchmarks were run on a fully loaded machine:
1[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Tasks: 116, 352 thr; 8 running
2[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Load average: 7.54 7.64 7.59
3[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Uptime: 14 days, 07:28:59
4[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
5[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
6[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
7[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
8[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
Mem[|||||||||||||||||||||||||||||||||||||||||||||||||| 35.6G/60.8G]
Swp[ 0K/0K]
PID USER PRI NI VIRT RES SHR S CPU%â–½MEM% TIME+ Command
449817 edh 20 0 45.7G 34.8G 112M S 793. 55.9 936h /usr/bin/python /usr/bin/ipython -i script/playground.py
449911 edh 20 0 45.7G 34.8G 112M R 99.8 55.9 101h /usr/bin/python /usr/bin/ipython -i script/playground.py
449913 edh 20 0 45.7G 34.8G 112M R 99.8 55.9 101h /usr/bin/python /usr/bin/ipython -i script/playground.py
449918 edh 20 0 45.7G 34.8G 112M R 99.8 55.9 120h /usr/bin/python /usr/bin/ipython -i script/playground.py
449909 edh 20 0 45.7G 34.8G 112M R 99.1 55.9 102h /usr/bin/python /usr/bin/ipython -i script/playground.py
449914 edh 20 0 45.7G 34.8G 112M R 99.1 55.9 101h /usr/bin/python /usr/bin/ipython -i script/playground.py
449915 edh 20 0 45.7G 34.8G 112M R 99.1 55.9 101h /usr/bin/python /usr/bin/ipython -i script/playground.py
449912 edh 20 0 45.7G 34.8G 112M R 98.4 55.9 102h /usr/bin/python /usr/bin/ipython -i script/playground.py
449910 edh 20 0 45.7G 34.8G 112M R 97.8 55.9 101h /usr/bin/python /usr/bin/ipython -i script/playground.py
565502 klm 20 0 41.6G 313M 151M S 2.0 0.5 0:58.04 /usr/lib/brave-bin/brave --type=renderer --field-trial-handle=5497587067748927688,
563438 klm 20 0 1379M 107M 71204 S 0.7 0.2 0:07.56 /usr/lib/Xorg vt7 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -
563557 klm 20 0 1138M 385M 182M S 0.7 0.6 0:06.74 /usr/lib/brave-bin/brave
564279 klm 20 0 848M 69248 55692 S 0.7 0.1 0:02.30 /usr/lib/brave-bin/brave --type=utility --utility-sub-type=audio.mojom.AudioServic
564290 klm 9 -11 671M 13736 9412 S 0.7 0.0 0:05.52 /usr/bin/pulseaudio --daemonize=no --log-target=journal
565585 klm 20 0 41.6G 313M 151M S 0.7 0.5 0:05.11 /usr/lib/brave-bin/brave --type=renderer --field-trial-handle=5497587067748927688,
566103 klm 20 0 9772 5356 3536 R 0.7 0.0 0:00.73 htop
1 root 20 0 169M 7760 4664 S 0.0 0.0 1:48.04 /sbin/init
In my case, using Saaze on a heavily loaded machine, runtimes previously were:
$ time php saaze build
Building static site in /home/klm/tmp/sndsaaze/build...
execute(): filePath()=/home/klm/tmp/sndsaaze/content/blog.yml, entries=1, totalPages=11, entries_per_page=30
execute(): filePath()=/home/klm/tmp/sndsaaze/content/music.yml, entries=1, totalPages=1, entries_per_page=30
execute(): filePath()=/home/klm/tmp/sndsaaze/content/pages.yml, entries=1, totalPages=1, entries_per_page=30
Finished creating 3 collections and 315 entries (3.46 secs / 10.79MB), md2html=2.1529788970947, MathParser=0.13162446022034
real 3.58s
user 2.92s
sys 0
swapped 0
total space 0
Now they went down:
$ time php saaze build
Building static site in /home/klm/tmp/sndsaaze/build...
execute(): filePath()=/home/klm/tmp/sndsaaze/content/blog.yml, entries=1, totalPages=11, entries_per_page=30
execute(): filePath()=/home/klm/tmp/sndsaaze/content/music.yml, entries=1, totalPages=1, entries_per_page=30
execute(): filePath()=/home/klm/tmp/sndsaaze/content/pages.yml, entries=1, totalPages=1, entries_per_page=30
Finished creating 3 collections and 315 entries (1.99 secs / 10.29MB), md2html=0.27019762992859, MathParser=0.13629722595215
real 2.12s
user 1.27s
sys 0
swapped 0
total space 0
date: "2021-07-13 19:30:00" title: "Performance Comparison C vs. Java vs. Javascript vs. LuaJIT vs. PyPy vs. PHP vs. Python vs. Perl" slug: blog-2021-07-13-performance-comparison-c-vs-java-vs-javascript-vs-luajit-vs-pypy-vs-php-vs-python-vs-perl draft: false categories: ["Programming"] tags: ["C", "Java", "Javascript", "node.js", "LuaJIT", "PHP", "Python", "Perl", "PyPy"] author: "Elmar Klausmeier" MathJax: true
prismjs: true
This post was automatically copied from Performance Comparison C vs. Java vs. Javascript vs. LuaJIT vs. PyPy vs. PHP vs. Python vs. Perl on eklausmeier.goip.de.
1. Introduction. I always wanted to benchmark PHP, to confirm myself that choosing PHP as a static site generator is not a dead-end, compared, for example, against node.js. PHP 7 has already made huge performance advancements. See PHP 7: Features and Performance Comparison:
- Drupal - Compared to previous versions, Drupal 8 runs 72 percent faster on PHP 7 when compared to previous versions.
- Wordpress - For WordPress, a PHP 7 runtime only executes 25M CPU instructions compared to just under 100M doing the same job on older PHP versions.
- Magento - For Magento, servers running PHP 7 are able to serve up to three times more requests as those running PHP 5.6.
Also, there were continuous improvements in PHP 7 and PHP 8, see PHP 8.1 Performance Is Continuing To Improve With Early Benchmarks.
2. Korol's and Zahariev's results. A specific comparison between PHP and node.js can be found in Viktor Korol's PHP vs NodeJS comparison and benchmarks, clearly favoring PHP. A performance comparison between PHP and various other languages was conducted in C++ vs. Python vs. PHP vs. Java vs. Others performance benchmark (2016 Q3). It shows that node.js is multiple times faster than PHP 7.
For the reader's convenience I reproduce the table from Ivan Zahariev, but leave out Rust, C#, Go, and Ruby:
| Language | real in s |
| C++ | 0.951 |
| PyPy | 1.496 |
| node.js | 1.837 |
| PHP 7 | 6.624 |
| Java 8 | 12.144 |
| Python 3.5 | 18.077 |
| Perl | 25.068 |
| Python 2.7 | 25.333 |
I had compared C vs. Lua vs LuaJIT and Java here, and I had previously benchmarked C vs. LuaJIT vs. various Lua versions vs. Pallene here.
3. Results. This time I again use the \(n\)-queens problem, i.e., how many times can \(n\) queens be put on an \(n\times n\) chess board without attacking any other queen. The programs in C, Python, PHP, Javascript (node.js), Lua, and Perl are given in 5. Programs. Task at hand is to compute from \(n=1\) to \(n=12\) all possible combinations. For example, for C I call time xdamcnt2 12. I ran the programs multiple times and took the lowest result. Results are "real" time in seconds, i.e., this includes "user" and "sys" times. Of course, all programs produced exactly the same results -- all computations are integer computations. Expected results are:
| n | 2 | 4 | 6 | 8 | 10 | 12 | 14 | |||||||
| combinations | 1 | 0 | 0 | 2 | 10 | 4 | 40 | 92 | 352 | 724 | 2,680 | 14,200 | 73,712 | 365,596 |
Runtimes on NUC and Odroid are given in below table:
| Language | NUC | Ryzen | Odroid |
| C | 0.17 | 0.15 | 0.44 |
| Java 1.8.0 | 0.31 | 0.22 | 108.17 |
| node.js 16.4 | 0.34 | 0.21 | 1.67 |
| LuaJIT | 0.49 | 0.33 | 2.06 |
| PyPy3 7.3.5 | 1.57 | 0.86 | n/a |
| PHP 8 | 3.23 | 2.35 | 42.38 |
| Python 3.9.6 | 12.29 | 7.65 | 168.17 |
| Perl 5.34 | 25.87 | 21.14 | 209.47 |
Conclusions:
- C is by far the fastest, by a factor of 2 on Intel to its nearest competitors: Java and Javascript. On Ryzen the difference is not so nuanced.
- Javascript and Java are almost similar in speed -- I didn't expect this result.
- Java's performance on ARM is terrible, even worse than Javascript, LuaJIT, and PHP combined. This means that very likely Java will run poorly on Apple's M1, or Amazon Graviton.
- Michael Pall's LuaJIT is a strong competitor to all other languages.
- PyPy is more than 7-times faster than Python.
- PHP 8 is faster than Python, but almost 10-times slower than Javascript, confirming the "adding numbers" benchmark as mentioned in the introduction from Viktor Korol, and in line with measurments from Ivan Zahariev.
- While C is roughly 2.5-times slower on ARM than on Intel, the other languages suffer a disproportionate degradation.
4. Machines used. Performance tests were run on Intel NUC Kit D54250WYKH, a quadcore i5-4250U machine.
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i5-4250U CPU @ 1.30GHz
CPU family: 6
Model: 69
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
Stepping: 1
CPU max MHz: 2600.0000
CPU min MHz: 800.0000
BogoMIPS: 3792.18
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht t
m pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid ap
erfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic m
ovbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ssbd ibrs
ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsave
opt dtherm ida arat pln pts md_clear flush_l1d
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 64 KiB (2 instances)
L1i: 64 KiB (2 instances)
L2: 512 KiB (2 instances)
L3: 3 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-3
Vulnerabilities:
Itlb multihit: KVM: Mitigation: VMX disabled
L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Meltdown: Mitigation; PTI
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Full generic retpoline, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Srbds: Vulnerable: No microcode
Tsx async abort: Not affected
Operating system and version:
$ uname -a
Linux nuc 5.12.15-arch1-1 #1 SMP PREEMPT Wed, 07 Jul 2021 23:35:29 +0000 x86_64 GNU/Linux
Performance tests were run on Ryzen 3400G.
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 PRO 3400G with Radeon Vega Graphics
CPU family: 23
Model: 24
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 1
Frequency boost: enabled
CPU max MHz: 3700.0000
CPU min MHz: 1400.0000
BogoMIPS: 7402.17
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb r
dtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe pop
cnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext p
erfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt s
ha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeass
ists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev sev_es
Virtualization features:
Virtualization: AMD-V
Caches (sum of all):
L1d: 128 KiB (4 instances)
L1i: 256 KiB (4 instances)
L2: 2 MiB (4 instances)
L3: 4 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-7
Vulnerabilities:
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, STIBP disabled, RSB filling
Srbds: Not affected
Tsx async abort: Not affected
Operating system and version:
$ uname -a
Linux ryzen 5.12.15-arch1-1 #1 SMP PREEMPT Wed, 07 Jul 2021 23:35:29 +0000 x86_64 GNU/Linux
Tests were run on an Odroid XU4, an octacore ARM machine.
$ lscpu
Architecture: armv7l
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: ARM
Model name: Cortex-A7
Model: 3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Stepping: r0p3
CPU max MHz: 1500.0000
CPU min MHz: 200.0000
BogoMIPS: 120.00
Flags: half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt vfpd32 lpae
Model name: Cortex-A15
Model: 3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Stepping: r2p3
CPU max MHz: 2000.0000
CPU min MHz: 200.0000
BogoMIPS: 120.00
Flags: half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt vfpd32 lpae
Operating system and version:
$ uname -a
Linux odroid 4.14.180-3-ARCH #1 SMP PREEMPT Sat Jun 5 22:29:47 UTC 2021 armv7l GNU/Linux
5. Programs. The C program. C compiler is gcc 11.1.0 and using flags -Wall -O3 -march=native.
#define abs(x) ((x >= 0) ? x : -x)
/* Check if k-th queen is attacked by any other prior queen.
Return nonzero if configuration is OK, zero otherwise.
*/
int configOkay (int k, int a[]) {
int z = a[k];
for (int j=1; j<k; ++j) {
int l = z - a[j];
if (l == 0 || abs(l) == k - j) return 0;
}
return 1;
}
long solve (int N, int a[]) { // return number of positions
long cnt = 0;
int k = a[1] = 1;
int N2 = N; //(N + 1) / 2;
loop:
if (configOkay(k,a)) {
if (k < N) { a[++k] = 1; goto loop; }
else ++cnt;
}
do
if (a[k] < N) { a[k] += 1; goto loop; }
while (--k > 1);
a[1] += 1;
if (a[1] > N2) return cnt;
k = 2 , a[2] = 1;
goto loop;
}
The Java program. Java is 1.8.0_292-b10.
class xdamcnt2 {
/* Check if k-th queen is attacked by any other prior queen.
Return nonzero if configuration is OK, zero otherwise.
*/
public static boolean configOkay (int k, int[] a) {
int z = a[k];
for (int j=1; j<k; ++j) {
int l = z - a[j];
if (l == 0 || Math.abs(l) == k - j) return false;
}
return true;
}
public static long solve (int N, int[] a) { // return number of positions
long cnt = 0;
int k = a[1] = 1;
int N2 = N; //(N + 1) / 2;
boolean flag;
for (;;) {
flag = false;
if (configOkay(k,a)) {
if (k < N) { a[++k] = 1; continue; }
else ++cnt;
}
do
if (a[k] < N) { a[k] += 1; flag = true; break; }
while (--k > 1);
if (flag) continue;
a[1] += 1;
if (a[1] > N2) return cnt;
k = 2; a[2] = 1;
}
}
...
The Javascript program. node.js is v16.4.2
/* Check if k-th queen is attacked by any other prior queen.
Return nonzero if configuration is OK, zero otherwise.
*/
function configOkay (k, a) {
var j;
let z = a[k];
for (j=1; j<k; ++j) {
let l = z - a[j];
if (l == 0 || Math.abs(l) == k - j) return 0;
}
return 1;
}
function solve (N, a) { // return number of positions
let cnt = 0;
let k = a[1] = 1;
let N2 = N; //(N + 1) / 2;
loop: for(;;) {
if (configOkay(k,a)) {
if (k < N) { a[++k] = 1; continue loop; }
else ++cnt;
}
do
if (a[k] < N) { a[k] += 1; continue loop; }
while (--k > 1);
a[1] += 1;
if (a[1] > N2) return cnt;
k = 2 , a[2] = 1;
}
}
The Python program. Python is 3.9.6. PyPy is 7.3.5 for Python 3.7.0.
# Check if k-th queen is attacked by any other prior queen.
# Return 'True' if configuration is OK, 'False' otherwise.
#
def configOkay (k, a):
z = a[k]
for j in range(1,k):
l = z - a[j]
if (l == 0 or abs(l) == k - j): return False
return True
def solve (N, a): # return number of positions
cnt = 0
k = a[1] = 1
N2 = N # (N + 1) / 2
while True:
flag = 0
if configOkay(k,a):
if k < N: k += 1; a[k] = 1; continue
else: cnt += 1
while True:
if a[k] < N: a[k] += 1; flag = 1; break
k -= 1
if k <= 1: break
if flag == 1: continue
a[1] += 1
if (a[1] > N2): return cnt
k = 2
a[2] = 1
The PHP program. PHP is 8.0.8.
<?php
/* Check if k-th queen is attacked by any other prior queen.
Return nonzero if configuration is OK, zero otherwise.
*/
function configOkay (int $k, &$a) {
$z = $a[$k];
for ($j=1; $j<$k; ++$j) {
$l = $z - $a[$j];
if ($l == 0 || abs($l) == $k - $j) return 0;
}
return 1;
}
function solve (int $N, &$a) { // return number of positions
$cnt = 0;
$k = $a[1] = 1;
$N2 = $N; //(N + 1) / 2;
loop:
if (configOkay($k,$a)) {
if ($k < $N) { $a[++$k] = 1; goto loop; }
else ++$cnt;
}
do
if ($a[$k] < $N) { $a[$k] += 1; goto loop; }
while (--$k > 1);
$a[1] += 1;
if ($a[1] > $N2) return $cnt;
$k = 2 ; $a[2] = 1;
goto loop;
}
The Perl program. Perl is 5.34.0
use strict;
# Check if k-th queen is attacked by any other prior queen.
# Return nonzero if configuration is OK, zero otherwise.
#
sub configOkay {
my ($k, $a) = ($_[0], $_[1]);
my $z = $a->[$k];
my ($j,$l);
for ($j=1; $j<$k; ++$j) {
$l = $z - $a->[$j];
if ($l == 0 || abs($l) == $k - $j) { return 0; }
}
return 1;
}
sub solve { # return number of positions
my ($N, $a) = ($_[0], $_[1]);
my $cnt = 0;
my $k = $a->[1] = 1;
my $N2 = $N; # (N + 1) / 2;
loop:
if (configOkay($k,$a)) {
if ($k < $N) { $a->[++$k] = 1; goto loop; }
else { ++$cnt; }
}
do {
if ($a->[$k] < $N) { $a->[$k] += 1; goto loop; }
} while (--$k > 1);
$a->[1] += 1;
if ($a->[1] > $N2) { return $cnt; }
$k = 2 ; $a->[2] = 1;
goto loop;
}